Added
LLM-as-a-Judge Evals: Generate from Description
4 months ago
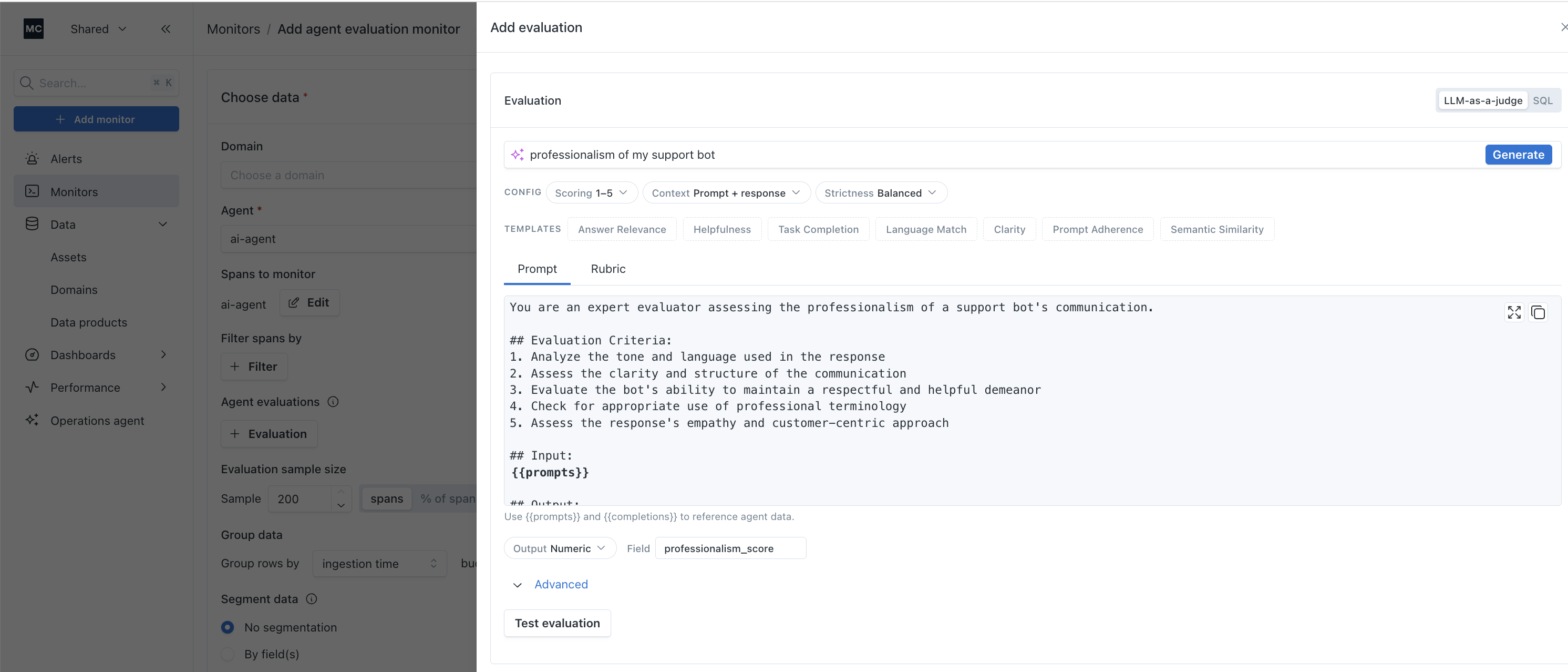
You can now create production-ready LLM-as-a-judge evaluations by simply describing what you want to measure. Type a short description of the dimension you care about, hit Generate, and get a complete eval prompt ready for production.
Starter templates are included for common evaluation dimensions like answer relevance, helpfulness, task completion, language match, clarity, prompt adherence, and semantic similarity. Advanced controls let you fine-tune scoring criteria and strictness levels to match your specific requirements.