Added
Evaluations in Metric Monitors
4 months ago
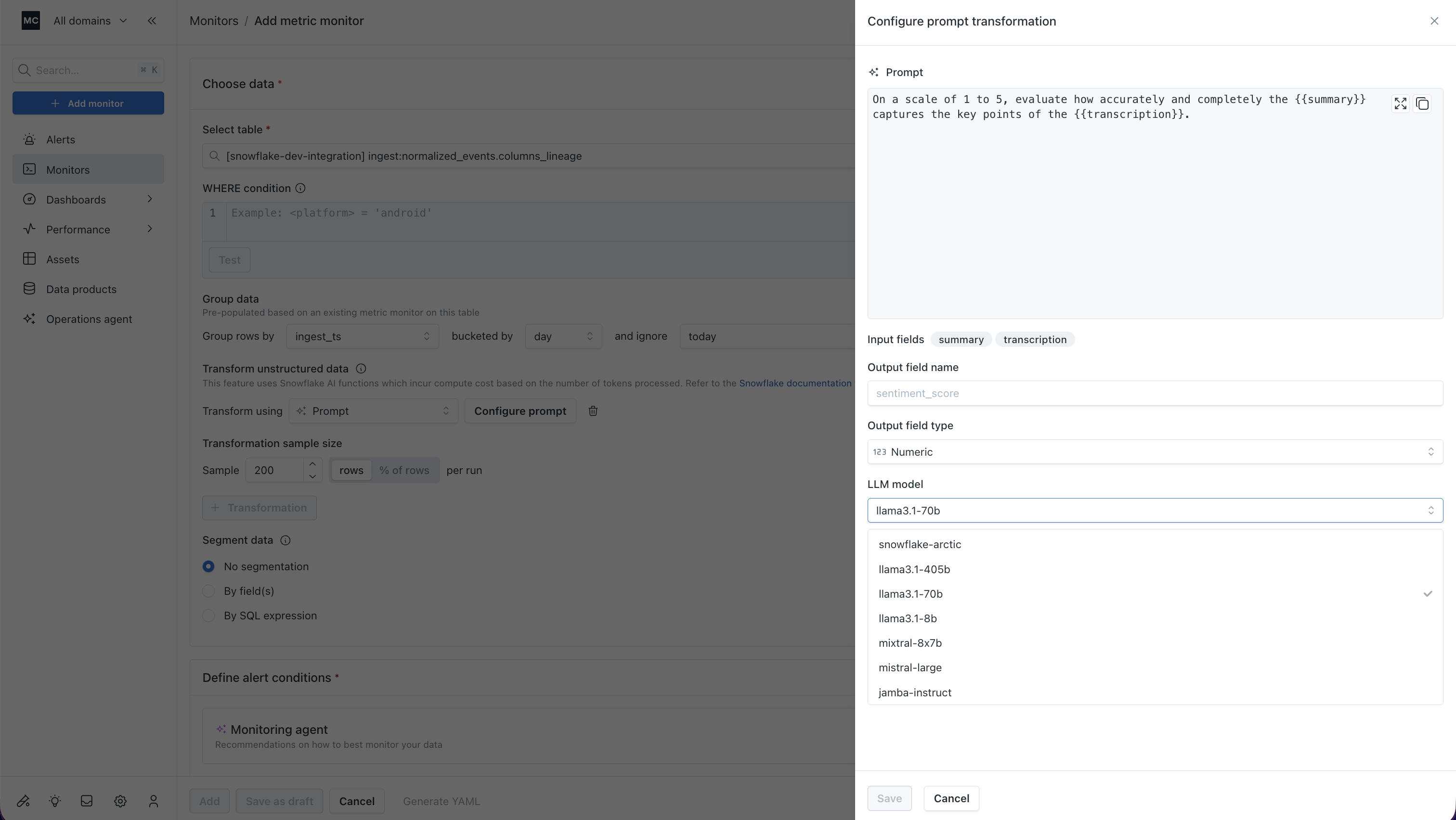
Metric monitors now support custom prompt-based evaluations on your tables — no external pipelines, no SQL hacks.
Write a prompt and plug in any table fields as variables (e.g., "Is {{SUMMARY}} an accurate summary of {{TRANSCRIPTION}}?"), pick your output type (string, numeric, or boolean), choose your LLM, and configure sampling. Monte Carlo handles the rest.
Whether your warehouse holds AI-generated summaries, extracted features, model scores, or anything in between — you have a native way to catch bad outputs in your tables before they become bad decisions. Available for Snowflake, Databricks, and BigQuery.
Learn more here: https://docs.getmontecarlo.com/docs/metric-monitors#configuring-a-prompt-transformation