Recommend configurations
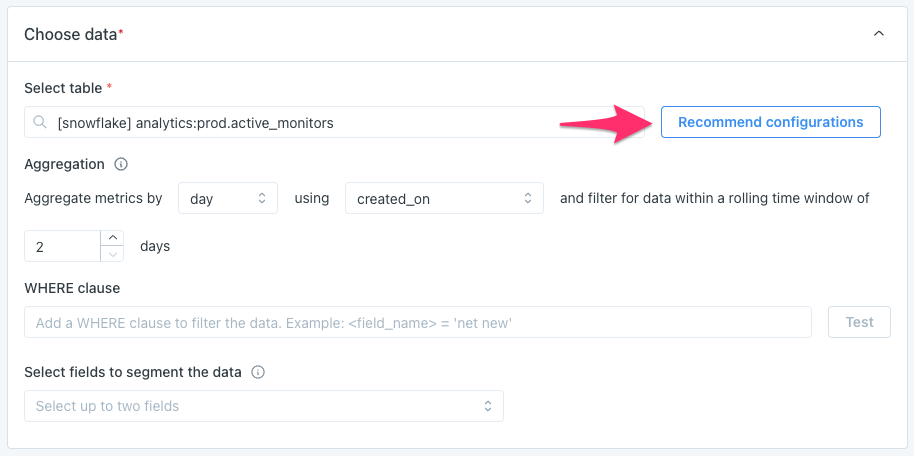
When creating or editing a Metric monitor, users have the option to Recommend configuration. This helps to configure certain settings to optimize the effectiveness of the monitor.
When Recommend configuration is clicked, Monte Carlo runs queries on the table in order to recommend:
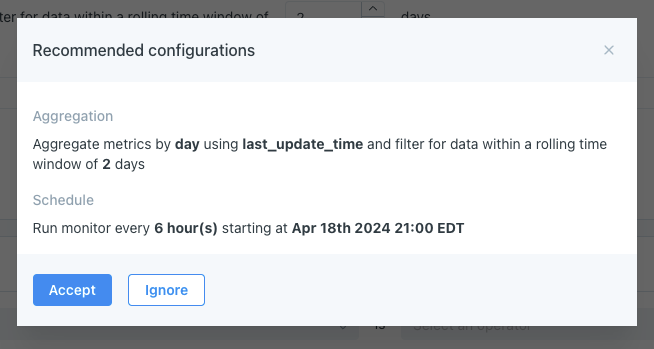
- Aggregation: this defines if the monitor will filter just for recent rows vs. full-table scans, and if those will be grouped into hourly or daily buckets. For example: Aggregate metrics by day using created_dt and filter for data within a rolling time window of 2 days*
- Schedule: this defines how often the monitor will run. For example: Run monitor every 6 hours starting at 21:00 EDT*
When these settings are not configured thoughtfully, the monitor may collect metrics on data that is not yet mature, or it may aggregate metrics in a way that introduces too much variance and desensitizes the machine learning.
It can take anywhere from a few seconds up to 2 minutes to generate a recommendation. Once available, users can then choose to accept or reject the recommendation. If accepted, it will overwrite any pre-selected settings for Aggregation and Schedule.
If it takes longer than 2 minutes to generate the recommendation, the query will be cancelled and the user will be asked to manually configure the monitor. This is to avoid accidentally long-running queries.
Factors included in the recommendation
Several factors are considered when generating a recommendation.
For Aggregation, considerations include:
- Is there a valid date field?
- Is there a valid time field?
- What is the distance of MAX timestamp from the current time?
- Will hourly vs daily buckets produce better row counts per sample for anomaly detection?
For Schedule, considerations include:
- How frequently is the table updated?
- Is the table a Key Asset or not?