End of life for Notebook-based Metadata Collection on Databricks
Monte Carlo has announced the end of life for Notebook-based Collection for the Databricks integration.
Customers have until June 1, 2024, to migrate to the SQL Warehouse integrations for Metadata collection. All new customers since October 1, 2023 have been onboarded using the SQL Warehouse integration and have experienced cost efficiencies, performance gains, and more control over what is ingested and monitored. Many existing customers have also migrated to SQL Warehouses as well.
Customers requiring the use of Clusters for running individual monitors are still able to use the Spark integration, but the SQL Warehouse integration is strongly encouraged for customers on Databricks.
Why was this change made?
When the Databricks integration was created in 2022, Databricks SQL Warehouses were not generally available (referred to as SQL Endpoints and were in beta). Since then, we have partnered closely with Databricks to develop the most efficient integration possible to collect metadata for data observability. SQL Warehouses better align with our other Warehouse and Lake integrations so we can best support customers and we have focused on improving this method of collection rather than spreading our efforts across both the Notebook and SQL Warehouse integrations.
Over the past few months, we have grown more confident that this is the best path forward for all of our Databricks customers.
What are additional benefits of this change?
- Significant performance gains running SQL queries for metadata collection and for monitors
- Anecdotally, cost-savings due to SQL efficiencies on SQL Warehouses
- Improved monitoring/observability of metadata collection and monitors by Monte Carlo support
- Ability for RCAs to be much more likely to complete since SQL Warehouse spin up time is faster than cluster spin up time
- Faster auto-shutdown when jobs are finished with SQL Warehouses
How do I make the change?
- Create a SQL Warehouse for Metadata Collection (these steps are also outlined here)
- For environments with 10,000 tables or fewer Monte Carlo recommends starting with a
2X-Small. - Most Metadata operations are executed in the driver, so a
2X-Smallshould be enough, but a larger SQL Warehouse might be required depending on the number and size of Delta tables. - ⚠️If using Unity Catalog, Glue, or the internal Databricks Metastore, the
Serverlesstype is recommended for cost efficiency reasons, butProis also supported. For External Hive MetastoresProis the only supported type -Serverlessis not supported.ClassicSQL Warehouses are not supported (while it will connect, there are significant issues with performance). - ⚠️ Set minimum and maximum number of clusters to 1 - counterintuitively, autoscaling can cause performance problems for metadata collection.
- Please reach out to your account representative for help right-sizing!
- For environments with 10,000 tables or fewer Monte Carlo recommends starting with a
- On your integrations settings, click the three-dots next to the
Databricks Metastore via Clusterintegration and click Migrate.
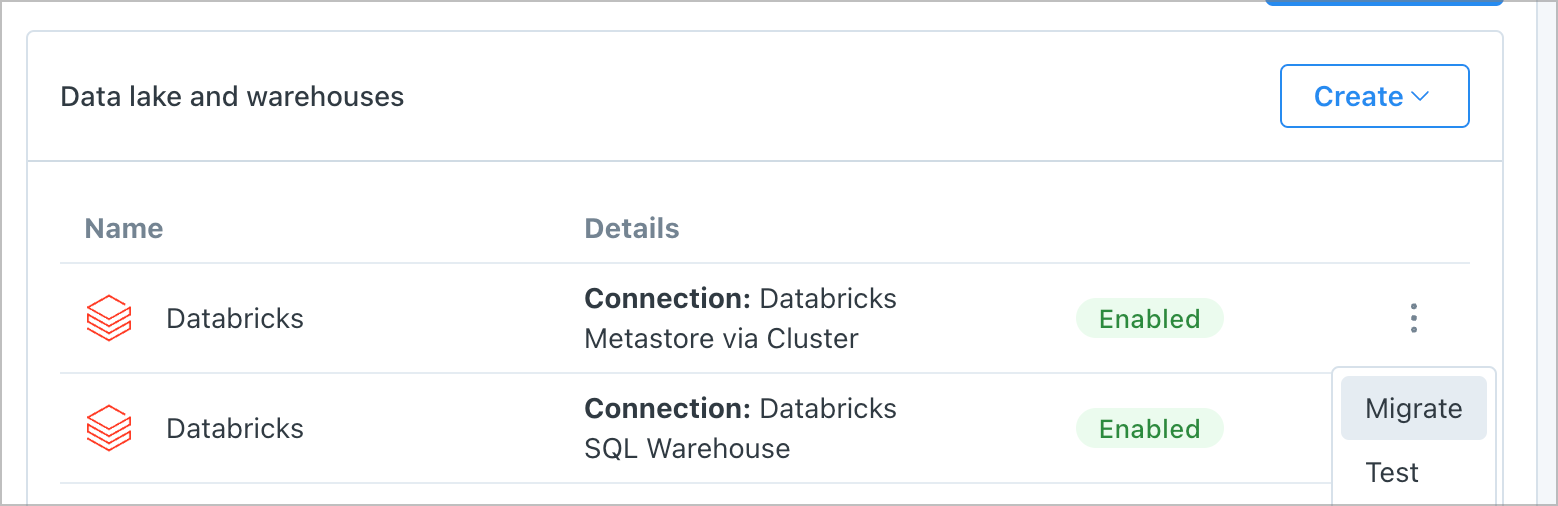
- Enter your Workspace URL and Personal Access / Service Principal Token. Please ensure that the token you are using has access to the SQL Warehouse you created.
- Enter the SQL Warehouse ID of the SQL Warehouse you created above.
- Click Migrate to test.
Will we lose access to any features?
The only loss is the ability to run metadata collection on a Cluster. The SQL Warehouse integration is a superset of all other features on the EOL Notebook integration.
What if the SQL Warehouse fails to work? Will my monitoring be affected?
If there is an issue that arises during your migration, Monte Carlo has the ability to apply Maintenance Window to all tables so that anomaly detection and model training is unaffected.
Updated about 1 year ago