Circuit breakers
Circuit breakers can be used to stop (or "circuit break") pipelines when data does not meet a set of quality or integrity thresholds. This can be useful for multiple purposes including, but definitely not limited to, checking if data does not meet your requirements between transformation steps, or after ETL/ELT jobs execute, but before BI dashboards are updated.
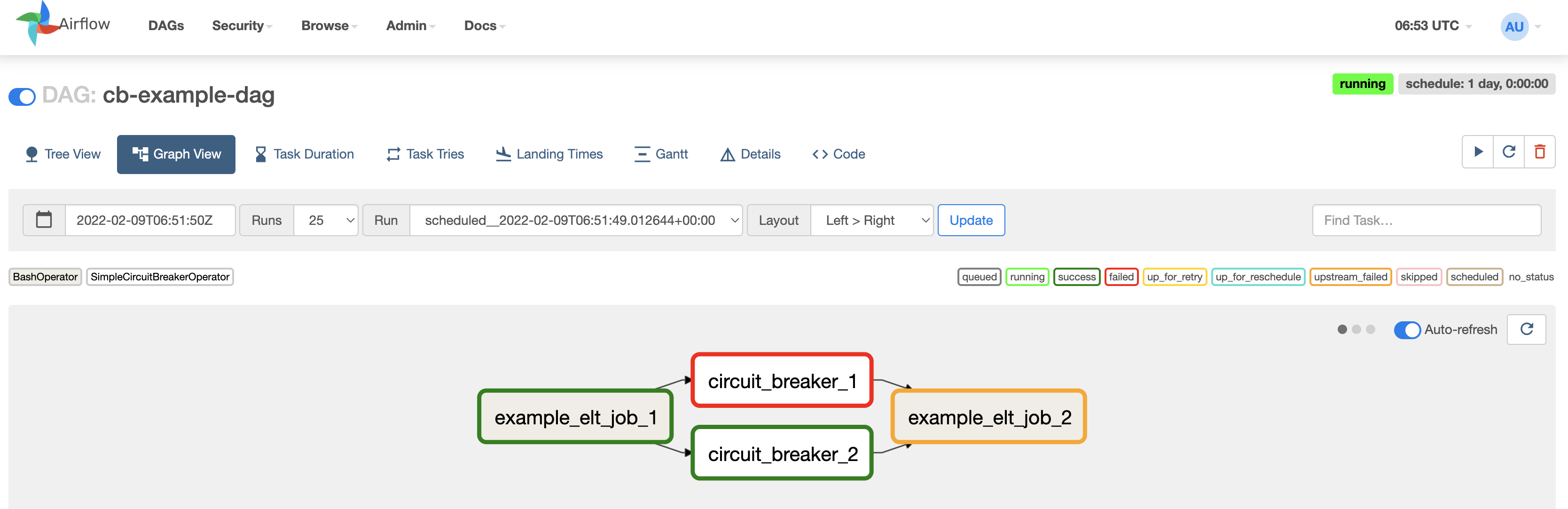
Example of an integrity test preventing a downstream task from executing using our airflow provider.
The following guide explains how to get started with circuit breakers. This includes:
- Finding all existing compatible monitors
- Creating a new compatible monitor
- Adding circuit breakers to your pipeline
- Advanced details
- Limitations
Word of caution: Prevent unintended data downtimeCircuit breakers provide an excellent way to prevent data issues from occurring in the first place. However, circuit breakers can also wreak havoc on pipelines when delayed jobs set off a chain reaction of data failures downstream.
Keep the following in mind when considering how you implement circuit breakers:
- When considering which monitors to implement, select only monitors with a run history where you have a good understanding of how often Incidents are triggered
- Start small by implementing circuit breakers in a handful of Airflow DAGs with a lot of visibility to catch when the breaker is triggered
- Select Custom SQL monitors where the underlying SQL executes quickly to avoid long query timeouts
Compatible monitor types
Circuit Breakers are supported across AWS, Azure, and GCP.
To circuit break your pipelines, you can use
- Validation monitors.
- Custom SQL monitors.
- Legacy freshness rules.
- Legacy volume rules using absolute threshold with an increase/decrease condition only.
These include both scheduled and unscheduled monitors. See here for more details on the difference between the two.
Via the Dashboard
To find a compatible rule in Monte Carlo, please visit the monitors page, and update the filter to only display compatible monitors (see Creating a new compatible monitor).
You can find the rule UUID by viewing monitor details for that rule you want to use. Save this value as you will need it to add the rule to your pipeline.
Via the CLI
Follow this guide to install and configure the CLI. Requires >= 0.18.0
The monitors list command with circuit_breaker_compatible as the monitor type can be used to conveniently list all relevant monitors with their description and UUIDs.
You should save the UUIDs for any monitors you want use as they will be needed to add the rule to your pipeline.
For reference, see help for this command below:
$ montecarlo monitors list --help
Usage: montecarlo monitors list [OPTIONS]
List monitors ordered by update recency.
Options:
--limit INTEGER Max number of monitors to list. [default:
100]
--monitor-type [CIRCUIT_BREAKER_COMPATIBLE|CUSTOM_SQL|TABLE_METRIC|FRESHNESS|VOLUME|STATS|CATEGORIES|JSON_SCHEMA]
List monitors with monitor_type
--namespace TEXT List only monitors in this namespace
--help Show this message and exit.# List all circuit breaker compatible rules
$ montecarlo monitors list --rule-type circuit_breaker_compatibleCreating a new compatible monitor
You can create a compatible monitor via the Dashboard, CLI (Monitors as Code) or the API/SDK.
Most monitor can either have a recurring schedule that runs automatically or be configured to only run when triggered manually. The latter are intended to be used only for circuit breakers (or another manual trigger), while the former (scheduled monitors) will also run outside of your pipelines based on the interval you specified. Using scheduled monitors for circuit breaking does not affect their normal execution, and can be helpful if you also want your quality checks to happen outside of your pipeline too. Generally, manually triggered monitors are recommended to prevent unnecessary queries on your warehouse outside of your transformation pipeline.
Via the Dashboard
Follow this guide to create a compatible rule in Monte Carlo.
An unscheduled rule is created by selecting "Manually triggered only" in the wizard.
Via the CLI
Follow this guide to create a monitor in Monte Carlo via Monitors as Code.
Compatible configurations include - custom_sql, freshness, and volume. See here for details on how to configure. For instance,
montecarlo:
custom_sql:
- name: example_circuit_breaker_rule
description: Test rule
sql: |
select foo from project.dataset.my_table
comparisons:
- type: threshold
operator: GT
threshold_value: 0
schedule:
type: manualmontecarlo:
custom_sql:
- description: Test rule
sql: |
select foo from project.dataset.my_table
comparisons:
- type: threshold
operator: GT
threshold_value: 0
schedule:
type: fixed
interval_minutes: 60
start_time: "2021-07-27T19:00:00"Adding circuit breakers to your pipeline
PrerequisitesThese steps require creating an API token. See here for details.
How you want to add a circuit breaker to your pipeline is based on your environment and pipelines. Monte Carlo offers multiple options. See the compatibility matrix below:
| SimpleCircuitBreakerOperator | pycarlo (features) | pycarlo (core) | API | |
|---|---|---|---|---|
| Airflow orchestrator | Yes | Yes | Yes | Yes |
| Other python orchestrator | No | Yes | Yes | Yes |
| Non-python orchestrator | No | No | No | Yes |
SimpleCircuitBreakerOperator
You can leverage the MCD Airflow provider to simply add a Circuit breaker to your existing Airflow DAGs.
This operator handles triggering, polling and breach evaluation for a rule and Raises an AirflowFailException if the rule condition is in breach when using an Airflow version newer than 1.10.11. Older Airflow versions raise an AirflowException.
This operator expects the following parameters:
mcd_session_conn_id: A SessionHook compatible connection. See basic usage below.rule_uuid: UUID of the rule (SQL Rule, Freshness Rule, or Volume Rule) to execute.rule_name: Name of the rule to execute (can be specified in Monitors as Code via thenameparameter)namespace: The Monitors as Code namespace (omit this if the monitor was created via the UI)runtime_variables: An dictionary of variable name to variable value. Required when running a Custom SQL monitor that uses runtime variables.
Note: pass either rule_name and namespace or rule_uuid. rule_name is preferred to avoid certain cases where a rule's UUID can change.
The following parameters can also be passed:
timeout_in_minutes[default=5]: Polling timeout in minutes. Note that The Data Collector Lambda has a max timeout of 15 minutes when executing a query. Queries that take longer to execute are not supported, so we recommend filtering down the query output to improve performance (e.g limit WHERE clause). If you expect a query to take the full 15 minutes we recommend padding the timeout to 20 minutes.fail_open[default=True]: Prevent any errors or timeouts when executing a rule from stopping your pipeline. RaisesAirflowSkipExceptionif set to True and any issues are encountered. It is recommended to set the Airflow Task trigger_rule param for any downstream tasks tonone_failedwhenfail_open=True.
On failing openBy default this operator fails open (
fail_open=True). What this means is if there are any errors during executing, processing or evaluating the rule your pipeline is not halted. Only actual breaches should be able to circuit-break or stop your pipelines.If you want to guarantee a rule passes (i.e. does not breach) set this parameter to
False.
fail_open=True (default) fail_open=False trigger_rule=all_success (default) CircuitBreaker task is marked as skippedon errors & timeouts; downstream tasks are marked asskipped.CircuitBreaker task is marked as failedon errors & timeouts; downstream tasks are marked asupstream_failed.trigger_rule=none_failed CircuitBreaker task is marked as skippedon errors & timeouts; downstream tasks run regardless. (recommended)CircuitBreaker task is marked as failedon errors & timeouts; downstream tasks are marked asupstream_failed.
Basic Usage:
- Install airflow-mcd from PyPI.
Normally this can be done by adding the python package to yourrequirements.txtfile for Airflow. - Create a Monte Carlo API Key with at least
Editorspermissions in under Settings > API > Account Service Keys.- Note: you don't need to create an Airflow integration in Monte Carlo to use Circuit Breakers, these integrations are used only for callbacks.
- Create a new Airflow
Monte Carlo DataConnection that is compatible with theSessionHook. This hook expects an AirflowMonte Carlo Dataconnection with the MCD API Key ID in the Login field and the MCD API Secret in the Password field.- Note: The
airflow-mcdpackage prior to versionv.0.2.0used thehttpconnection type. - Note:
Monte Carlo Data Gatewayconnection type does not support Circuit Breakers operations, you must selectMonte Carlo Dataas the connection type.
- Note: The
- Click the Test button to test the connection. You should see a "Connection successfully tested" message.
- Save the connection.
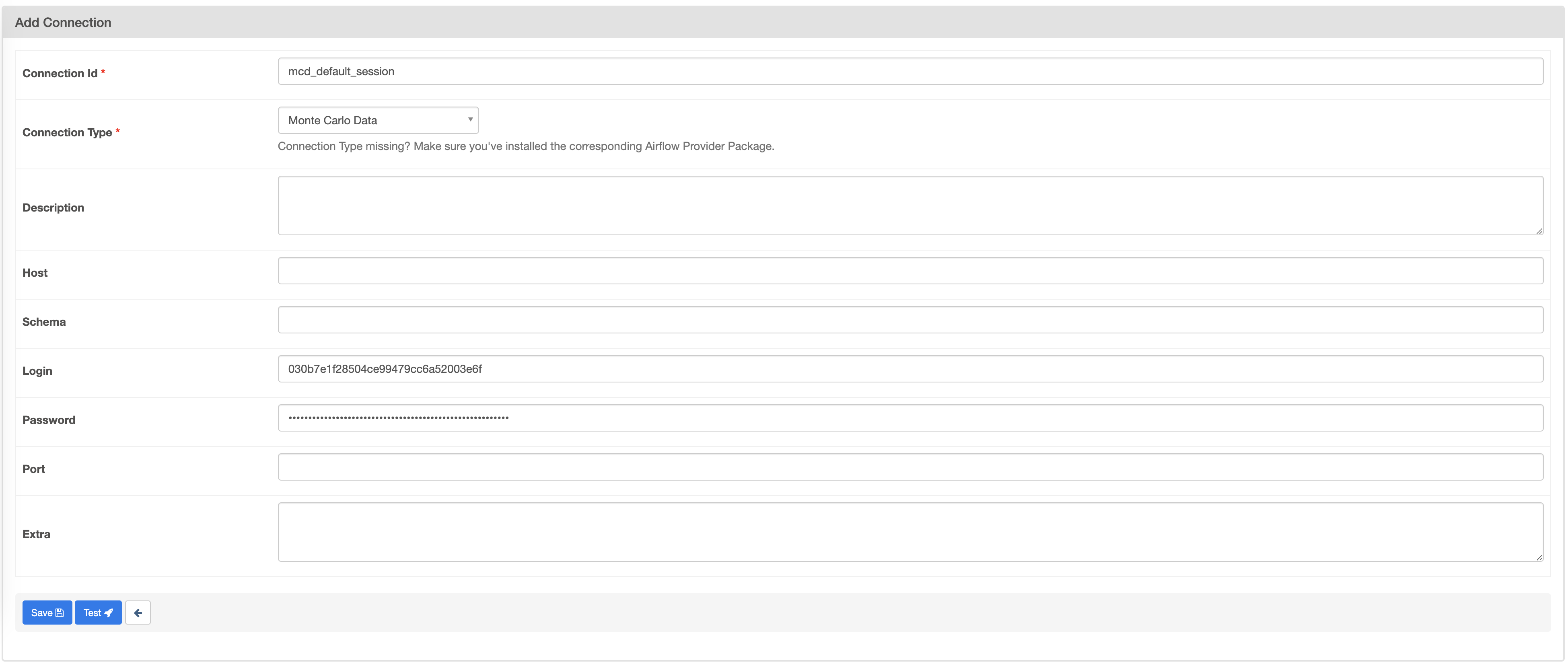
Creating a connection example
- Add the
SimpleCircuitBreakerOperatoroperator to your Airflow DAG. For instance,
from datetime import datetime, timedelta
from airflow import DAG
try:
from airflow.operators.bash import BashOperator
except ImportError:
# For airflow versions <= 2.0.0. This module was deprecated in 2.0.0.
from airflow.operators.bash_operator import BashOperator
from airflow_mcd.operators import SimpleCircuitBreakerOperator
mcd_connection_id = 'mcd_default_session'
with DAG('sample-dag', start_date=datetime(2022, 2, 8), catchup=False, schedule_interval=timedelta(1)) as dag:
task1 = BashOperator(
task_id='example_elt_job_1',
bash_command='echo I am transforming a very important table!',
)
breaker = SimpleCircuitBreakerOperator(
task_id='example_circuit_breaker',
mcd_session_conn_id=mcd_connection_id,
rule_name='<RULE_NAME>',
namespace='<RULE_NAMESPACE>',
)
task2 = BashOperator(
task_id='example_elt_job_2',
bash_command='echo I am building a very important dashboard from the table created in task1!',
trigger_rule='none_failed',
)
task1 >> breaker >> task2If you prefer you can also extend the BaseMcdOperator and SessionHook to include your own logic, processing using our SDK or any other dependencies. This operator and hook are useful outside of customizing circuit breaking too (e.g. creating custom lineage after a task completes).
Pycarlo
Follow this guide to install and configure the SDK.
We highly recommend you review the basic usage from the link above before proceeding.
You can leverage the SDK (features or core) in any python orchestrator or tool.
For instance, with Airflow, you can use a PythonOperator to execute python callables.
See Pycarlo (features) and Pycarlo (core) for more information.
Pycarlo (features)
Pycarlo (features) are an extension of our core SDK, which provides additional convenience by performing operations like combining queries, polling, paging and more.
For circuit breakers we offer methods to trigger, poll and chain both. For instance,
from pycarlo.features.circuit_breakers import CircuitBreakerService
service = CircuitBreakerService(print_func=print)
if service.trigger_and_poll(namespace='<RULE_NAMESPACE>', rule_name='<RULE_NAME>'):
raise SystemExitIf using runtime variables, you can pass them in the runtime_variables property, like this:
service.trigger_and_poll(namespace='<RULE_NAMESPACE>', rule_name='<RULE_NAME>', runtime_variables={"<your_var>":"a value"})You can use pydoc to retrieve any documentation on these methods. For instance,
pydoc pycarlo.features.circuit_breakers.servicePycarlo (core)
Pycarlo (core) provides convenient programmatic access to execute all MC queries and mutations. This can be used to further customize usage of circuit breakers vs what is already provided out of the box in features.
For circuit breakers the following two operations allow you to trigger and check the status of rule executions. See Advanced details for more information.
- Trigger -
trigger_circuit_breaker_rule_v2.
from pycarlo.core import Mutation, Client
mutation = Mutation()
mutation.trigger_circuit_breaker_rule_v2(namespace='<RULE_NAMESPACE>', rule_name='<RULE_NAME>').__fields__('job_execution_uuids')
job_execution_uuids = Client()(mutation).trigger_circuit_breaker_rule_v2.job_execution_uuidsIf using runtime variables, you can pass them in the runtime_variables property, like this:
mutation.trigger_circuit_breaker_rule_v2(namespace='<RULE_NAMESPACE>', rule_name='<RULE_NAME>', runtime_variables=[{"name": "<your var>", "value": "a value"}])- Check state -
get_circuit_breaker_rule_state_v2.
# Note that this example only checks the state once, this needs to be repeated until the status is in a term state.
# See advanced details for an explanation of states.
from pycarlo.core import Client, Query
query = Query()
query.get_circuit_breaker_rule_state_v2(job_execution_uuids=[str('<JOB_UUID>')]).__fields__('status', 'log')
circuit_breaker_states = Client()(query).get_circuit_breaker_rule_state_v2API
For any non-python environments you can always leverage our APIs. Like pycarlo (core) this consists of a trigger mutation and a series of status check queries. See Advanced details for more information.
- Trigger -
triggerCircuitBreakerRuleV2
curl --location --request POST 'https://api.getmontecarlo.com/graphql' \
--header 'x-mcd-id: <MCD_ID>' \
--header 'x-mcd-token: <MCD_TOKEN>' \
--header 'Content-Type: application/json' \
--data-raw '{"query":"mutation triggerCircuitBreakerRuleV2 {\n triggerCircuitBreakerRuleV2(ruleName:\"<RULE_NAME>\"){\n jobExecutionUuids\n }\n}","variables":{}}'If using runtime variables, you can pass them in the runtimeVariables property, like this:
triggerCircuitBreakerRuleV2(ruleName: "<your rule>", runtimeVariables: [{"name": "<your_var>", "value": "a value"}])- Check state -
getCircuitBreakerRuleStateV2
# Note that this example only checks the state once, this needs to be repeated until the status is in a term state.
# See advanced details for an explanation of states.
curl --location --request POST 'https://api.getmontecarlo.com/graphql' \
--header 'x-mcd-id: <MCD_ID>' \
--header 'x-mcd-token: <MCD_TOKEN>' \
--header 'Content-Type: application/json' \
--data-raw '{"query":"query getCircuitBreakerRuleStateV2 {\n getCircuitBreakerRuleStateV2(jobExecutionUuids: [\"<JOB_UUID>\"]){\n status\n log\n }\n}","variables":{}}'Using variables
Custom SQL monitors can reference variables in their SQL queries. When running a circuit breaker on a monitor that uses variables, all the combinations will be executed at once and the check will pass only if no alerts are triggered.
If using runtime variables, you must pass the runtime variable values when running the circuit breaker. The means to pass the variables depends on how you are running the circuit breaker. Check the details in the above section.
Advanced details
If you are a user of pycarlo (core), the API or just curious how to interpret the results from the underlying requests:
When triggering
Triggering a circuit breaker rule returns a list of job UUIDs. These IDs should be used in state polls until the status is in a term state. Custom SQL monitors create one job UUID for each query executed over your data store (e.g. when the monitor is defined over multiple tables, it will create one job per table, when it has different variables, it will create one job per combination of variables).
When getting the state
The state query contains two core fields in the response -
- The
statusas a string - The
logas a list
The status field contains multiple states, and are mostly used for internal tracing. From a user's perspective only the term states need to be tracked. This includes PROCESSING_COMPLETE and HAS_ERROR. The former indicates the rule has finished executing, processing and evaluating while the latter indicates an error has occurred.
The last value of the log list will always contains details about the state. If in HAS_ERROR you should see details about the exception, while in PROCESSING_COMPLETE you should see details about the breach.
A breach count of 0 indicates no breach has occurred.
[{...}, {
"stage": "EVALUATOR",
"timestamp": "2022-02-11T19:36:37.947347",
"payload": {
"breach_count": 1
}
}][{...}, {
"stage": "DATA_COLLECTOR_CHILD",
"timestamp": "2022-02-11T19:36:37.947347",
"payload": {
"error": "...",
"traceback": ["..."]
}
}]Limitations
Monitors with same UUID executed within 5 minutes of each other share the same execution. If you need to run the same rule in parallel we recommended creating multiple monitors with the same query and threshold. This limitation is not applied if the monitor uses runtime variables.
Query execution delays are primarily limited by the concurrency of the collection agents or cluster load. Please reach out to your Monte Carlo representative if you are affected by this.
When updating a rule that was created via Monitors as Code or with an automatic threshold, its UUID may change. To avoid this issue, please specify name for the rule in Monitors as Code and use the rule name and namespace to trigger the rule instead of the UUID.
Network Access Control
You can restrict access to the Circuit Breaker endpoint by IP address using Network Access Control Lists. See Network Access Control for setup and configuration details.
Updated 17 days ago