Custom SQL
Custom SQL monitors let users write their own tests using SQL. The flexibility of Custom SQL makes them a good fallback for use cases that cannot be addressed with Metrics, Validations, or Comparisons.
To configure custom SQL monitors as code, see the Custom SQL Monitor MaC reference.
Both manual and automatic (machine learning) thresholds are available with Custom SQL monitors. Users can also use default or custom Templates to cut down on the need to write redundant SQL.
Creating Custom SQL Monitors
Custom SQL monitors can be created from the Create Monitor page or Assets page. Configuration steps include:
Define SQL
Write the query that will be evaluated against the threshold. Settings include:
Warehouse: if your Monte Carlo environment is connected to more than one data source, the user can here select which one to query.
Set threshold using:
- Count of rows: the query will be wrapped in a SELECT COUNT, so that the count of rows returned by the query will be compared to the threshold.
- Value returned by query: the query should return one row with one numeric column, which will be compared to the threshold. This option is not available if data sampling has been disabled or if your data collector is below version
3563.
SQL query: users can input their own custom SQL, or select from templates. Some default templates are available, and custom templates can also be created. Users can also click a button to "Generate query with Monitoring Agent" and provide a written prompt. Some notes on performance of the queries:
- The SQL query must take less than 15 minutes to run. We recommend filtering on partitions and indexes to minimize query time.
- When testing the SQL query from the app, it must take less than 30 seconds to run. You can add a
limitto reduce query time, or test the query in your warehouse.
Advanced options:
- Static variables: users can embed one or more static {{variables}} in their SQL to help scale out their tests. There is a limit of 200 combinations of variable values per Custom SQL monitor.
- Runtime variables: users can embed one or more runtime {{variables}} in their SQL if their use case requires populating values dynamically via the UI or API.
- Investigation query: an additional optional SQL query that runs when the Custom SQL monitor is breached. Use this to return additional details or rows that will be helpful for investigation of the issue. The results of this query are limited to 5,000 rows (or 500 rows for warehouses that have not opted into the increased limit - reach out via our Support Agent to enable).
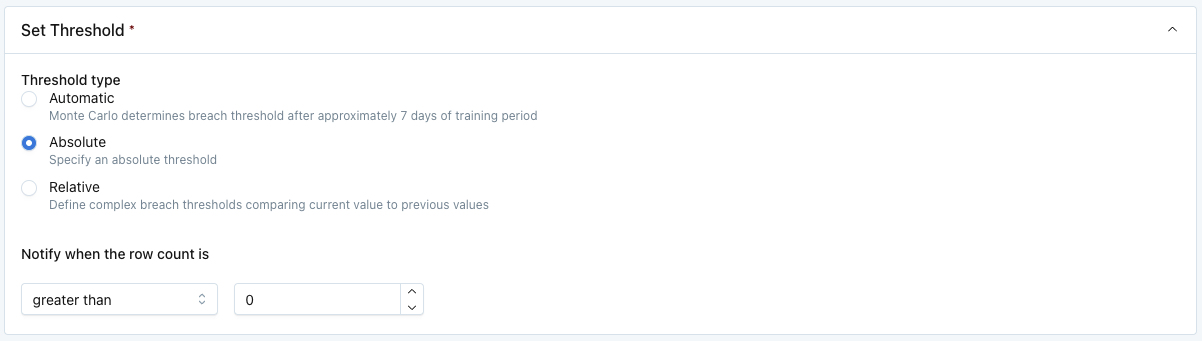
Set Threshold
Set the conditions that will trigger an alert. There are three options for threshold type:
- Automatic: machine learning will determine a threshold. This can take several days to a couple weeks to train, depending on how frequently the monitor is run and how consistent the results are.
- Absolute: user defines a manual threshold. For example, "Notify when the row count is greater than 0."
- Relative: user defines a threshold that is relative to past results of the monitor. For example, "Notify when the value returned is greater than 200% of the max of the previous 7 days."
- Percentage of total rows: user defines a threshold as a percentage of a baseline total row count. Requires a baseline query that returns the total row count to compare against. Only available when Set threshold using is set to Count of rows. For example, "Notify when more than 2% of total rows fail the check."
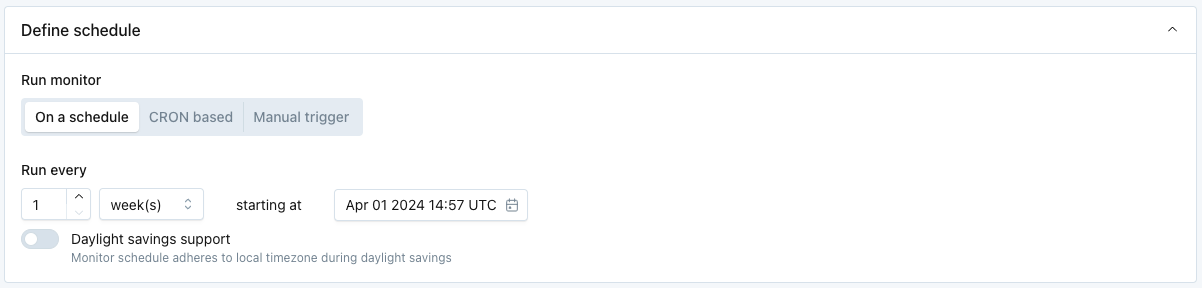
Define Schedule
Select when the monitor should run. There are several options:
- On a schedule: Input a regular, periodic schedule. Options for handling daylight savings are available in the advanced dropdown.
- CRON based: Input a cron expression to run on a schedule specified by the cron. Options for handling daylight savings are available in the advanced dropdown.
- By trigger:
- Manual trigger: Select this option when you want to manually trigger using the
Runbutton on the monitor description page, or programmatically via the runMonitor API call. Helpful for use with circuit breakers. - When a table is updated: The monitor will run when Monte Carlo sees that the table has been updated. This logic uses the history of table updates that Monte Carlo gets through its hourly collection of metadata. The run will occur up to 30 minutes after an update, but not more than once every 2 hours. Use the Run periodically if trigger doesn't fire toggle to control whether the monitor also runs on a fallback schedule (every 48 hours by default) when no table update is detected.
- When a job or task completes: The monitor will run when Monte Carlo detects a successful job or task execution, but not more frequently than every 2 hours. Use the Run periodically if trigger doesn't fire toggle to control whether the monitor also runs on a fallback schedule (every 48 hours by default) when no job or task executions are detected.
- Manual trigger: Select this option when you want to manually trigger using the
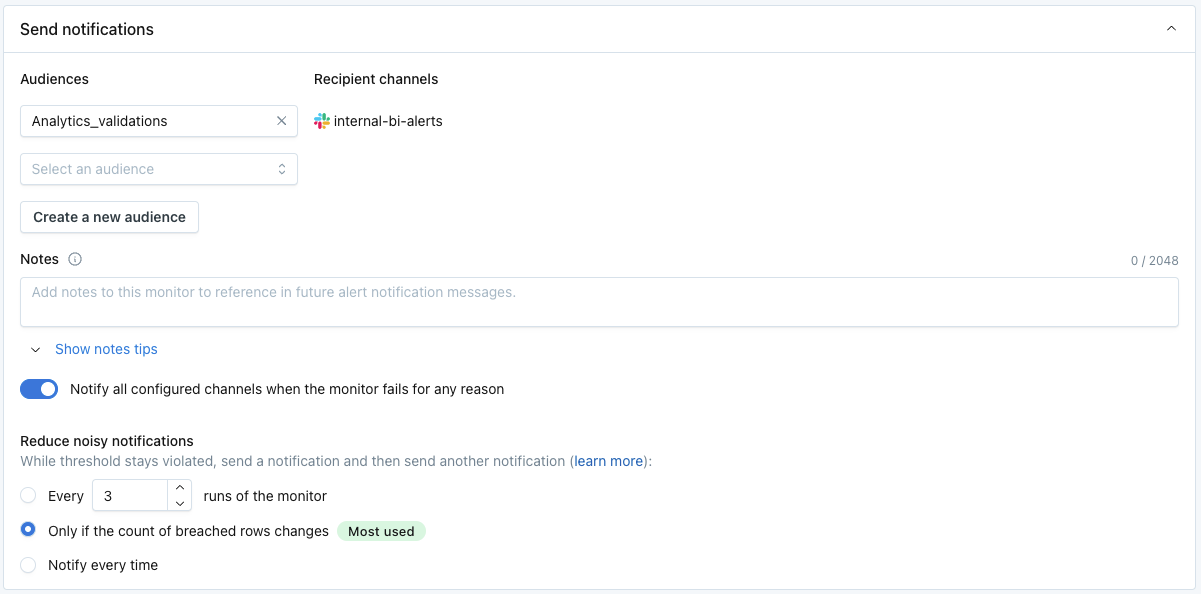
Send Notifications
Select which audiences should receive notifications when an anomaly is detected.
Text in the Notes section will be included directly in notifications. The "Show notes tips" dropdown includes details on how to @mention an individual or team if you are sending notifications to Slack, or parameterize values from breached rows into notifications.
In addition, there are options to reduce noisy notifications. This helps to reduce alert fatigue from monitors that frequently breach.
Add Detail
Add metadata about the monitor, such as the Description, Tags, the priority of alerts generated by this monitor, and a Data Quality Dimension. This section is identical across all custom monitor types in Monte Carlo.
Viewing Breached Rows from Custom SQL monitors
When a Custom SQL monitor creates an alert, the user can see which rows were returned by the query. Note, this only happens by default when using the Count of rows option in the Define SQL section. If using Value returned by query, you can still view rows returned by an investigation query.
The alert shows up to 5,000 rows returned by the query to aid with incident investigation (or 500 rows for warehouses that have not opted into the increased limit). To enable the 5,000 row limit for your warehouse, please reach out via our Support Agent.
Rows will not be available if:
- The data collector version is too old (requires version
2307or newer) - The customer has opted out of data sampling for the warehouse
- The Custom SQL monitor has a relative threshold
- The Custom SQL monitor has a threshold of 500 or more
Note for data lakes: output sampling for data lakes will add a LIMIT 500 to the query, so the resulting metric will be capped at 500 rows. This means that if the UI displays a value of 500, the unwrapped query could return more than 500 rows. This limitation does not apply to Custom SQL monitors for data warehouses, which report the full row count even with sampling enabled.
Tips for Notes
Contents of the Notes section of Custom SQL monitors will be passed through to notifications. This makes it a helpful place to explain what to do in case of a breach, how to interpret the results, link out to a run book, @mention a user or user group, and more.
Notes support rich-text formatting, including bold, italic, underline, strike-through, lists, links, and code blocks. Rich-text channels display these styles, while text-only channels show a plain-text equivalent.
Monitor properties can be dynamically inserted into Notes through variables. Supported variables include Created by , Last updated at, Last updated by, Priority, Tags and—for Validation and Custom SQL monitors—Query Result.
Including Query results in Notes inserts values returned by your SQL query into the alert notification. You can add Query Result through the variable selector or by using the manual syntax {{query_result:field_name}}, replacing field_name with the desired column.
When using the manual query_result syntax:
Parameterizing 1 field will result in a comma separated list. A maximum of 50 values or 1,000 characters will be displayed in the notification. For example, {{query_result:sale_id}} would display as:
abc123, def456, hij789
You can parameterize up to 5 fields in sequence. A maximum of 50 rows or 1,000 characters will be displayed in the notification. For example, {{query_result:date, price, sale_id}} would display as:
Jan 1, $100, abc123
Feb 1, $250, def456
Mar 1, $175, hij798
If you're sending notifications to Slack, you can use their formatting guide to enrich the Notes. For example:
- Tag users: use <@W123> and replace W123 with a Slack member ID. The ID can be found in Slack by clicking More in a member's profile, then Copy member ID.
- Tag user groups: use <!subteam^G123> and replace G123 with a Slack user group ID. The ID is at the end of the URL in Slack when viewing the group’s profile.
Some users have even incorporated Slack user IDs into their SQL results, and then parameterized them into their Slack alerts to dynamically @mention the appropriate users for different segments of data. Example:

Updated 12 days ago