BigQuery
What is BigQuery?
BigQuery is a fully managed enterprise data warehouse that helps you manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence. BigQuery's serverless architecture lets you use SQL queries to answer your organization's biggest questions with zero infrastructure management. BigQuery's scalable, distributed analysis engine lets you query terabytes in seconds and petabytes in minutes.
Why Connect BigQuery to Monte Carlo?
Connecting your BigQuery account to Monte Carlo, and giving us access to the data within is essential for Monte Carlo to function. Monte Carlo needs to be able to collect the metadata of your tables in BigQuery to enable our Freshness and Volume Table monitors. With access to the query logs of those tables, we will be able to build table and field lineage. With the ability to run SQL queries on those tables, Monte Carlo can run advanced monitors to analyze the data in those tables.
Monte Carlo is a Data + AI Observability tool after all, so the biggest step in getting value from it is letting it observe your data!
After connecting BigQuery here is what you can expect to see:
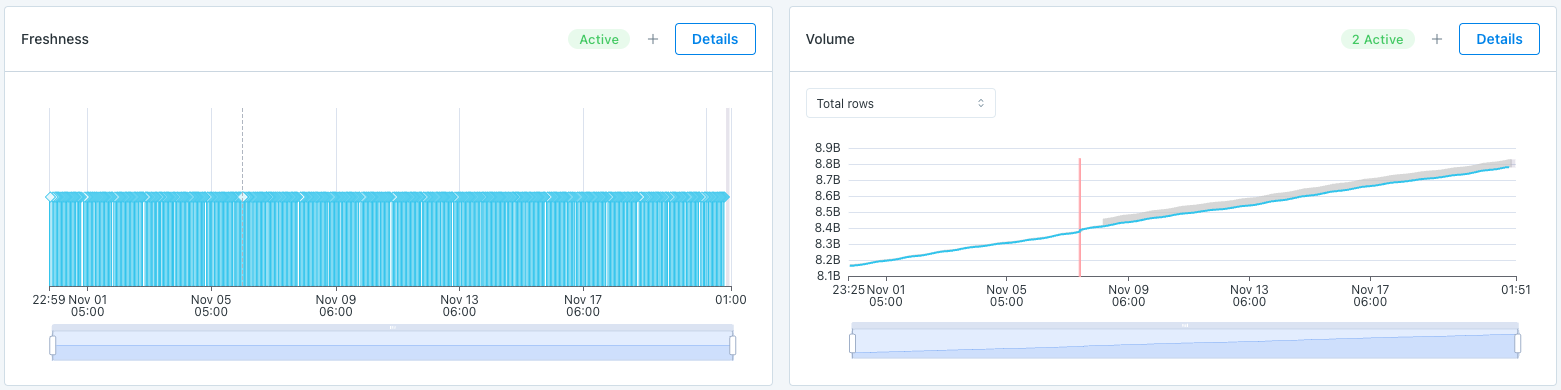
Freshness and Volume:
Our freshness and volume monitors are active by default. By collecting metadata on your tables, Monte Carlo’s machine learning algorithm can set automatic thresholds to alert when a table has gone too long without an update, and when an abnormal amount of rows are added or deleted.
Query Logs:
When giving access to query logs Monte Carlo is able to show the amount of read and write queries on a table, and give you access to the details of those queries. Monte Carlo can even highlight when a query appears to have failed.
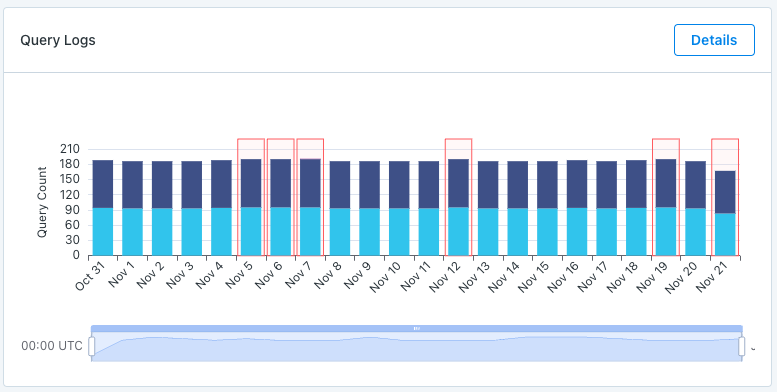
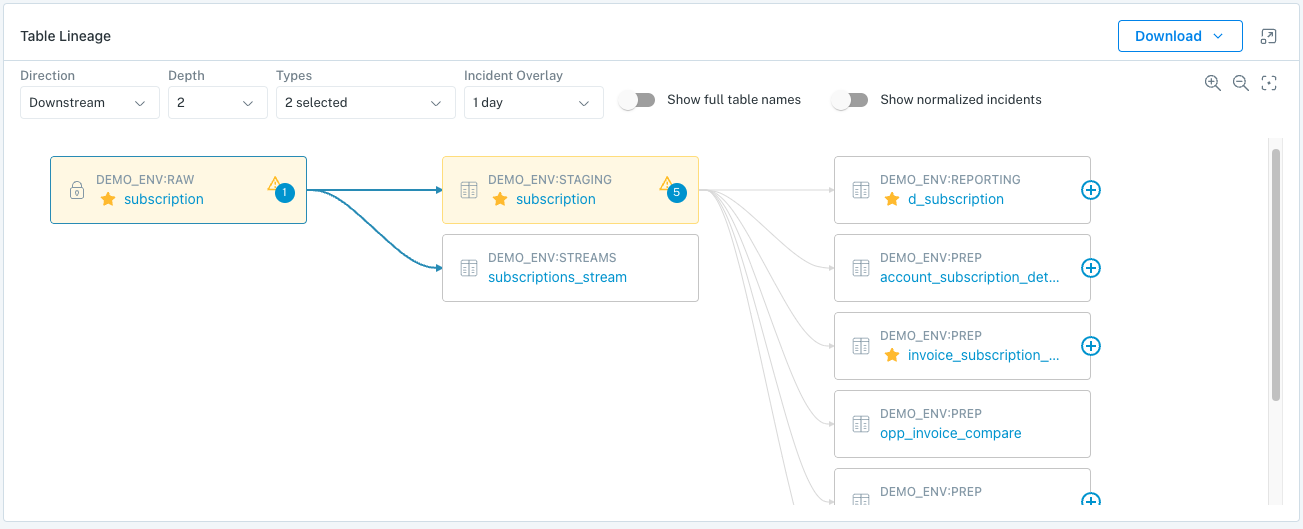
Table Lineage:
Monte Carlo is able to map the connections between your tables, and can show upstream and downstream connections. We can even connect anomalies that are detected in upstream tables to anomalies in downstream tables.
Monitor & Lineage Support
Below are the monitors and lineage support for the BigQuery integration today. Please reach out to your Monte Carlo representative if you have requirements for additional Monitors.
| Category | Monitor / Lineage Capabilities | Support |
|---|---|---|
| Table Monitor | Freshness | ✅ |
| Table Monitor | Volume | ✅ |
| Table Monitor | Schema Changes | ✅ |
| Metric Monitor | Metric | ✅ |
| Metric Monitor | Comparison | ✅ |
| Validation Monitor | Custom SQL | ✅ |
| Validation Monitor | Validation | ✅ |
| Job Monitor | Query performance | ✅ |
| Lineage | Lineage | ✅ |
Connecting BigQuery
Now that we know the value connecting BigQuery to Monte Carlo can bring, here are the necessary steps to set up the integration.
Admin credentials requiredTo make the read only service user for Monte Carlo, you will need owner permissions on BigQuery.
This guide explains how to create a read-only service account for Monte Carlo on BigQuery.
To review all steps necessary to integrate a data warehouse with Monte Carlo, please see here.
Creating a service account for a single BigQuery project
First, create a role for Monte Carlo's service account:
- Under IAM & Admin, go to the Roles section in your Google Cloud Platform console.
- Select the project to which your BigQuery warehouse belongs using the combo box on the top left of your dashboard.
- Click the Create Role button at the top of the tab.
- Give the new role a name. We recommend "Data Reliability Monitor".
- Change the Role launch stage to "General Availability".
- Click Add Permissions and add the permissions specified below to the role. To make the process faster, consider filtering the permission list by the role BigQuery Admin.
Now, create a service account:
- Under IAM & Admin, go to the Service Accounts section in your Google Cloud Platform console.
- Click the Create Service Account button at the top of the tab.
- Give the account a name and continue. We recommend naming the account "monte-carlo".
- Assign the role you previously created to the service account and continue.
- Click the Create Key button, select JSON as the type and click Create. A JSON file will download – please keep it safe as it grants access to your BigQuery data.
- Click Done to complete the creation of Monte Carlo's service account.
Finally, upload the JSON file you downloaded into Monte Carlo's onboarding wizard to finalize the integration.
Monitoring multiple projects using Monte Carlo
Allowing Monte Carlo's service account to access multiple projects can help with the following use cases:
- Tracking multiple datasets spread across more than one BigQuery project.
- Tracking query logs and lineage generated by users associated with more than one project.
To add an additional project to Monte Carlo's service role:
- Select the project using the combo box on the top left of the Google Cloud Platform console.
- Create a role that grants BigQuery access with the appropriate permissions following the instructions above. Optionally, you may use the following command in your terminal to copy the role over from another project (this is much quicker!):
gcloud iam roles copy- Under Access, go to the IAM section in your Google Cloud Platform console.
- Click the Add button, provide Monte Carlo's service account email address and click Save.
You may add any number of projects to Monte Carlo's service account.
Permissions and Roles Monte Carlo requires
bigquery.datasets.get
bigquery.datasets.getIamPolicy
bigquery.jobs.get
bigquery.jobs.list
bigquery.jobs.listAll
bigquery.jobs.create
bigquery.tables.get
bigquery.tables.getData
bigquery.tables.list
storage.buckets.list
storage.buckets.get
storage.objects.list
storage.objects.get
resourcemanager.projects.get
roles:
bigquery.metadataViewerBigQuery Permissions
| BigQuery Permission | Monte Carlo Requirement |
|---|---|
| bigquery.datasets.get | Get metadata about a dataset. Allows Monte Carlo to see the INFORMATION_SCHEMA views as well as list out available Datasets in BigQuery. |
| bigquery.datasets.getIamPolicy | Read a table's IAM policy. Allows Monte Carlo to read a list of available Datasets in BigQuery. Datasets store tables in a project. |
| bigquery.jobs.get | Get data and metadata on any job (query) in BigQuery. Allows Monte Carlo to read BigQuery query logs. |
| bigquery.jobs.list | List all jobs and retrieve metadata on any job submitted by any user. For jobs submitted by other users, details and metadata are redacted. Allows Monte Carlo to get Metadata on BigQuery query logs. This includes data such as start time, end time, and amount of data processed. |
| bigquery.jobs.listAll | List all jobs and retrieve metadata on any job submitted by any user. Allows Monte Carlo to get Metadata on BigQuery query logs. |
| bigquery.jobs.create | Run jobs (including queries) within the project. Allows Monte Carlo to run SELECT queries on the Information Schema and tables to be monitored. |
| bigquery.tables.get | Get BigQuery table metadata. Allows Monte Carlo to get table Metadata. Includes table creation time, number of rows, and byte size of the data. |
| bigquery.tables.getData | Get table data. This permission is required for querying table data. Allows Monte Carlo to run select queries for opt-in monitors on aggregated statistics. |
| bigquery.tables.list | List tables and metadata on tables. Allows Monte Carlo to see table Metadata and see all tables in a dataset. |
| resourcemanager.projects.get | Read project metadata. Allows Monte Carlo to list available GCP Projects to iterate through in order to collect BigQuery Metadata. Note that Monte Carlo Service Account can only see the list of the Projects that the Service Account has been provided access to, therefore this permission is necessary. |
| bigquery.metadataViewer | Read BigQuery table metadata. Allows Monte Carlo to get table metadata from the INFORMATION_SCHEMA views. Note that there is overlap with the permissions set listed above, this role allows the Monte Carlo Service Account to read from the views used to fetch table and column metadata. |
External Table Permissions
The following permissions are required for External Tables in BigQuery.
| BigQuery Permission | Monte Carlo Requirement |
|---|---|
| storage.buckets.list | List buckets in a project. Also read bucket metadata, excluding IAM policies, when listing. Allows Monte Carlo to see metadata of External Tables. |
| storage.buckets.get | Read bucket metadata, excluding IAM policies, and list or read the Pub/Sub notification configurations on a bucket. Allows Monte Carlo to get metadata of External Tables. |
| storage.objects.list | List objects in a bucket. Also read object metadata, excluding ACLs, when listing. Allows Monte Carlo to see metadata of External Tables. |
| storage.objects.get | Read object data and metadata, excluding ACLs. Allows Monte Carlo to get metadata of External Tables. |
Limitations
- With nested struct data types, Field Lineage is not available
- BigQuery Iceberg (BigLake-managed) tables — Monte Carlo collects metadata for Iceberg tables, but freshness information may not be available through the standard collection mechanism. See the FAQ below for details and a workaround using the push ingestion model.
FAQ
Why are my BigQuery Iceberg tables missing freshness data?
Monte Carlo's BigQuery collector retrieves table metadata from system views that do not include freshness (last modified time) for Iceberg (BigLake-managed) tables. Volume data (row count and byte size) is collected normally.
Google is rolling out the storage_last_modified_time column in INFORMATION_SCHEMA.TABLE_STORAGE for Iceberg tables, but as of April 2026 this is not yet available globally for all projects. Note that this column reflects when the data stored in the table was last modified — metadata-only changes (e.g. description updates) do not update this timestamp.
Workaround — Push Ingestion: You can use Monte Carlo's Push Ingestion API to collect freshness and volume directly from INFORMATION_SCHEMA.TABLE_STORAGE and push it to Monte Carlo. We have published ready-to-run example scripts for this:
BigQuery Iceberg Push Ingestion Scripts
These scripts:
- Discover Iceberg tables by filtering on
managed_table_type = 'BIGLAKE'inTABLE_STORAGE - Collect freshness, volume, and schema metadata
- Push the data to Monte Carlo via the pycarlo SDK
- Support a
--only-freshness-and-volumeflag for fast periodic pushes (recommended hourly) - Support query log collection and push as well
The repository README includes a full walkthrough, prerequisites, and recommended automation cadence.
Why are my BigQuery Iceberg tables showing zero row counts?
Row counts for Iceberg tables may appear as zero in Monte Carlo because the standard BigQuery metadata source does not always report accurate row counts for BigLake-managed tables. The push ingestion scripts mentioned above collect row counts from INFORMATION_SCHEMA.TABLE_STORAGE which provides accurate volume data for Iceberg tables.
If I am pushing BigQuery Iceberg tables metadata, do I need to also push query logs?
No. Query logs are collected automatically for BigQuery Iceberg tables so there is no need to push the query logs for these.
How can I validate Monte Carlo has access to my assets?
After completing the Bigquery integration setup, your Bigquery assets should appear in the Monte Carlo Assets page between a few minutes and one hour. If you don't see your assets after this time period, you can run a validation test to troubleshoot the connection:
- Navigate to Settings → Integrations
- Find your Bigquery integration and click on it
- Select the specific connection you want to test
- Click the Test button from the connection menu
This validation test will help identify any configuration issues that might be preventing your assets from appearing.
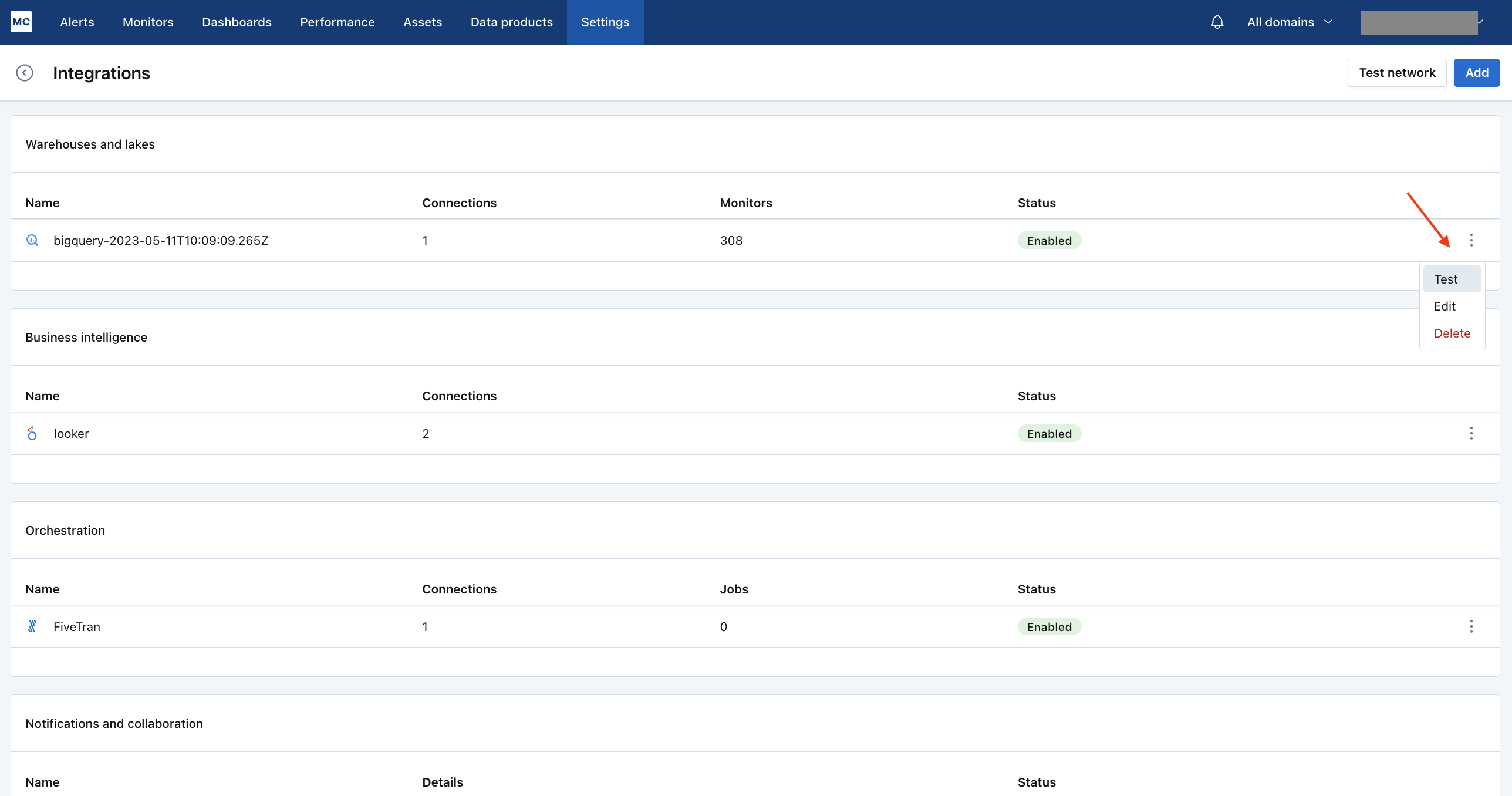
When running the validation test, you should see all green checkmarks. If any errors are encountered, the system will provide specific steps to resolve them.
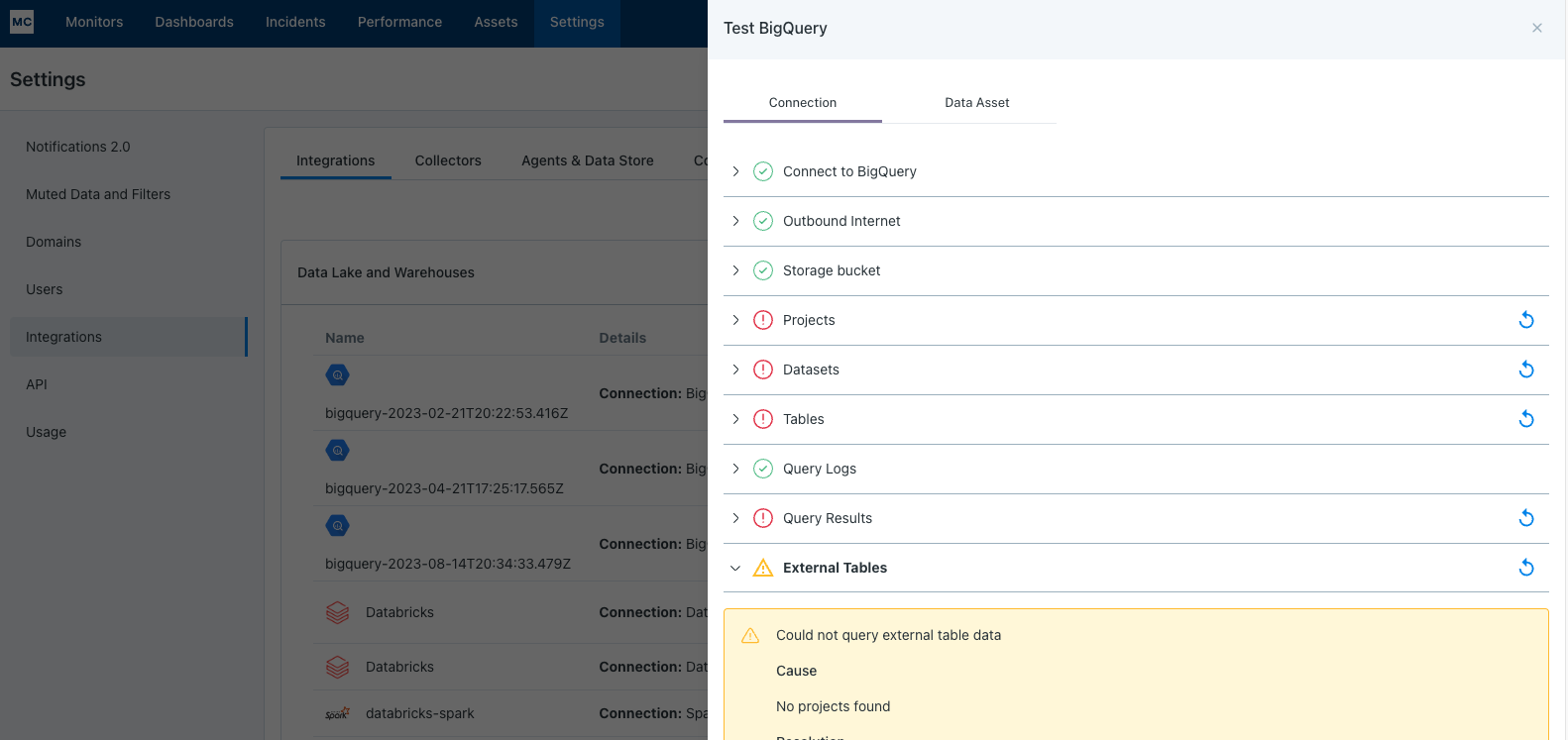
If assets from a specific database or schema are missing you can use the Data Asset validation to test our ability to access them:
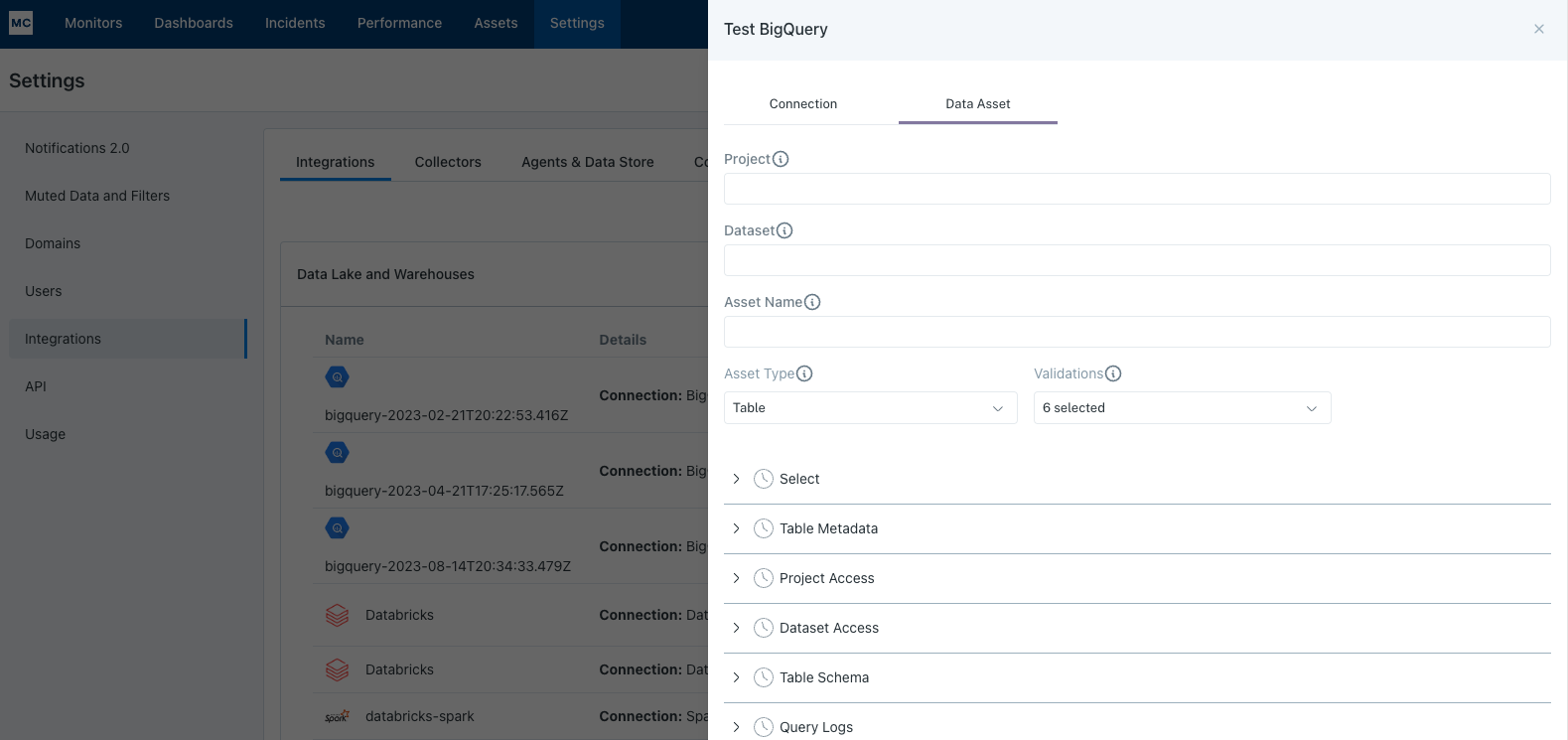
Note: Lineage can take up to 24 hours due to batching.
What should I do after rotating my service account key, or if I see an invalid_grant: Invalid JWT Signature error?
invalid_grant: Invalid JWT Signature error?This error means Monte Carlo is authenticating with a service account key that is no longer valid — most often because the key was rotated or recreated in GCP but not updated everywhere Monte Carlo stores it. If your BigQuery integration connects through a GCP Agent or GCS Data Store, the key is stored in two places — the integration and the data store / agent deployment — and both must be updated, starting with the data store. If the integration and data store use different service accounts, update each with a current key for its own account. See Rotating Keys for the full steps.
Updated about 2 months ago