Redshift
What is Redshift?
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift Serverless lets you access and analyze data without all of the configurations of a provisioned data warehouse.
Why Connect Redshift to Monte Carlo?
Connecting your Redshift account to Monte Carlo, and giving us access to the data within is essential for Monte Carlo to function. Monte Carlo needs to be able to collect the metadata of your tables in Redshift to enable our Freshness and Volume Table monitors. With access to the query logs of those tables, we will be able to build table and field lineage. With the ability to run SQL queries on those tables, Monte Carlo can run advanced monitors to analyze the data in those tables.
Monte Carlo is a Data + AI Observability tool after all, so the biggest step in getting value from it is letting it observe your data!
After connecting Redshift here is what you can expect to see:
Freshness and Volume:
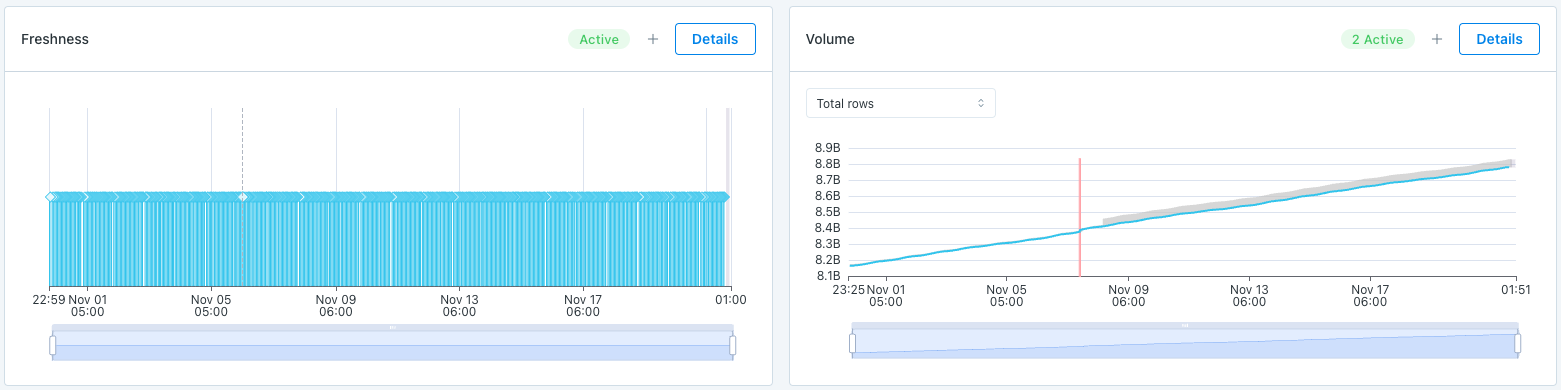
Our freshness and volume monitors are active by default. By collecting metadata on your tables, Monte Carlo’s machine learning algorithm can set automatic thresholds to alert when a table has gone too long without an update, and when an abnormal amount of rows are added or deleted.
Query Logs:
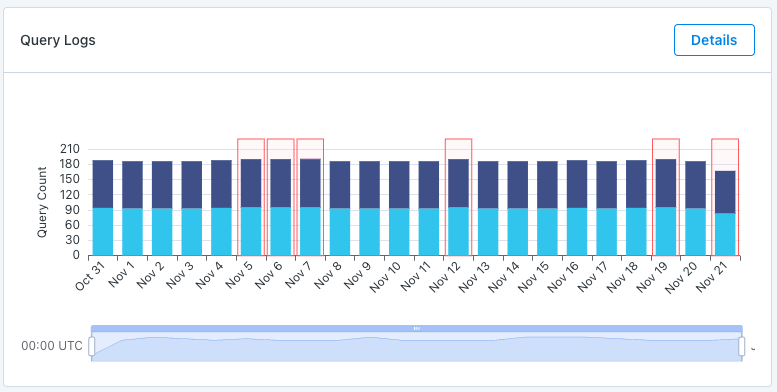
When giving access to query logs Monte Carlo is able to show the amount of read and write queries on a table, and give you access to the details of those queries. Monte Carlo can even highlight when a query appears to have failed.
Table Lineage:
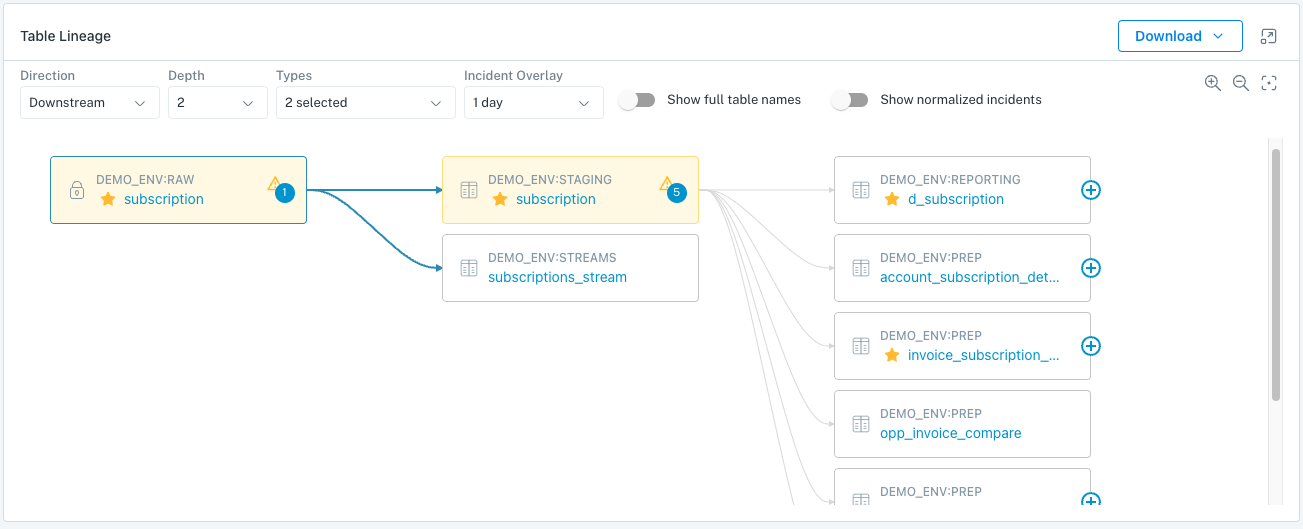
Monte Carlo is able to map the connections between your tables, and can show upstream and downstream connections. We can even connect anomalies that are detected in upstream tables to anomalies in downstream tables.
To review all steps necessary to integrate a data warehouse with Monte Carlo, please see here.
Monitor & Lineage Support
Below are the monitors and lineage support for the Redshift integration today. Please reach out to your Monte Carlo representative if you have requirements for additional monitors.
| Category | Monitor / Lineage Capabilities | Support |
|---|---|---|
| Table Monitor | Freshness | ✅ |
| Table Monitor | Volume | ✅ |
| Table Monitor | Schema Changes | ✅ |
| Metric Monitor | Metric | ✅ |
| Metric Monitor | Comparison | ✅ |
| Validation Monitor | Custom SQL | ✅ |
| Validation Monitor | Validation | ✅ |
| Job Monitor | Query performance | ✅ |
| Lineage | Lineage | ✅ |
Creating a service account
Admin credentials requiredTo make the read only service user for Monte Carlo, you will need admin credentials to your Redshift cluster.
Please use the following SQL snippet to create a service account for Monte Carlo:
CREATE USER <username> PASSWORD ‘<password>’ SYSLOG ACCESS UNRESTRICTED
GRANT SELECT ON svv_table_info to <username>
GRANT SELECT ON ALL TABLES IN SCHEMA <schema_name> [, …] to <username>
GRANT USAGE ON SCHEMA <schema_name> [, …] to <username>
GRANT USAGE ON SCHEMA <external_schema> [, …] to <username>
ALTER DEFAULT PRIVILEGES FOR USER <user_creating_tables> [, …] IN SCHEMA <schema_name> [, …] GRANT SELECT ON TABLES TO <username>Before using the snippet, you will need to populate the following:
- <username>: Service account username, typically "monte_carlo".
- <password>: Strong password to be used by the service account user.
- <schema_name>: Redshift schema(s) to be monitored. Please note you can provide a list of schemas in a single statement.
- <external_schema>: Redshift Spectrum schema(s) – where external tables are defined – to be monitored. Please note you can provide a list of schemas in a single statement.
- <user_creating_tables>: Redshift user(s) that create/update tables and external tables, typically the user(s) used by your ETL jobs. Please note you can provide a list of such users in a single statement.
Please note:
- syslog permissions allow Monte Carlo to to read query logs from all users.
- select permissions on svv_table_info allow Monte Carlo to to read metadata about tables in your warehouse.
- select and usage permissions on schemas allow Monte Carlo to track health for tables in the given schemas.
- usage permissions on external schemas allow Monte Carlo to to track health for external tables in the given schemas.
- Default privileges set for ETL users make sure that Monte Carlo maintains access to tables as ETL jobs run and update/create tables.
For control over which assets are ingested and monitored, use Usage controls.
FAQs
Can I monitor all databases in my deployment?
Yes, this feature is now in public preview. Reach out via our Support Agent if you would like this feature enabled for your integration.
Why am I missing views in Monte Carlo?
If you are using late binding views in your pipeline, please note that Monte Carlo will not pull in these views by default, meaning they will be unavailable to set advanced monitors on. Since these views only exist at the moment they are referenced, there is no data to collect from the cluster's system level views during our hourly collections. You can tell you are using a late binding view if the statement with no schema binding exists in the view definition. Please see the Redshift documentation for more information.
If setting monitors on these views is important to you, Monte Carlo does have the ability to ingest them! However, the way we collect these views is slightly different than the way we collect the rest of the cluster metadata due to the aforementioned reasoning, and so one side effect of enabling this on your collection jobs is catalog bloat. Historically, when we have enabled this type of collection for users, we have seen the amount of cluster resources we had to use to collect metadata increase.
If you are interested in this functionality or want to learn more about your options, please reach out to your Monte Carlo representative or our Support Agent for more information.
How can I validate Monte Carlo has access to my assets?
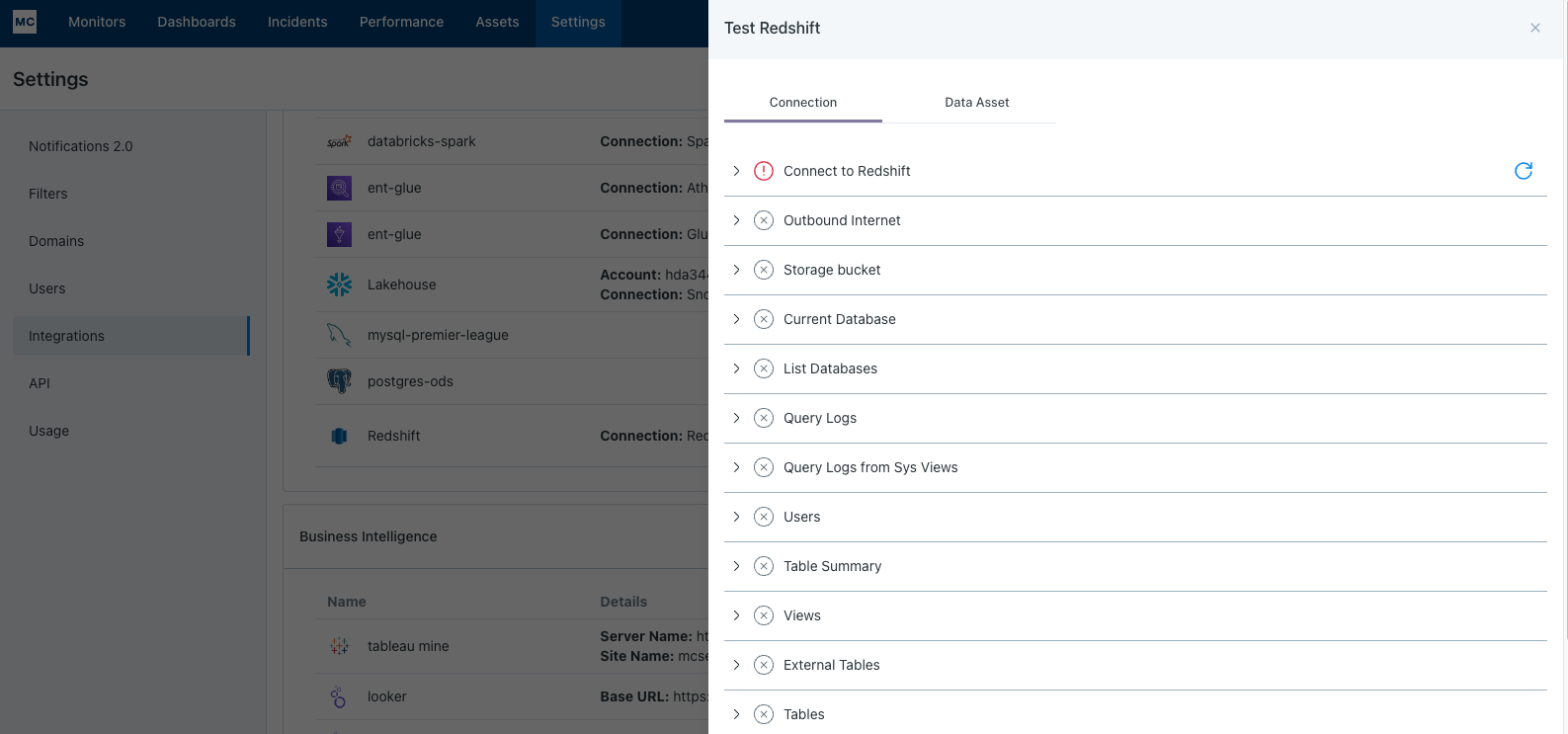
After completing the Redshift integration setup, your Redshift assets should appear in the Monte Carlo Assets page between a few minutes and one hour. If you don't see your assets after this time period, you can run a validation test to troubleshoot the connection:
- Navigate to Settings → Integrations
- Find your Redshift integration and click on it
- Select the specific connection you want to test
- Click the Test button from the connection menu
This validation test will help identify any configuration issues that might be preventing your assets from appearing.
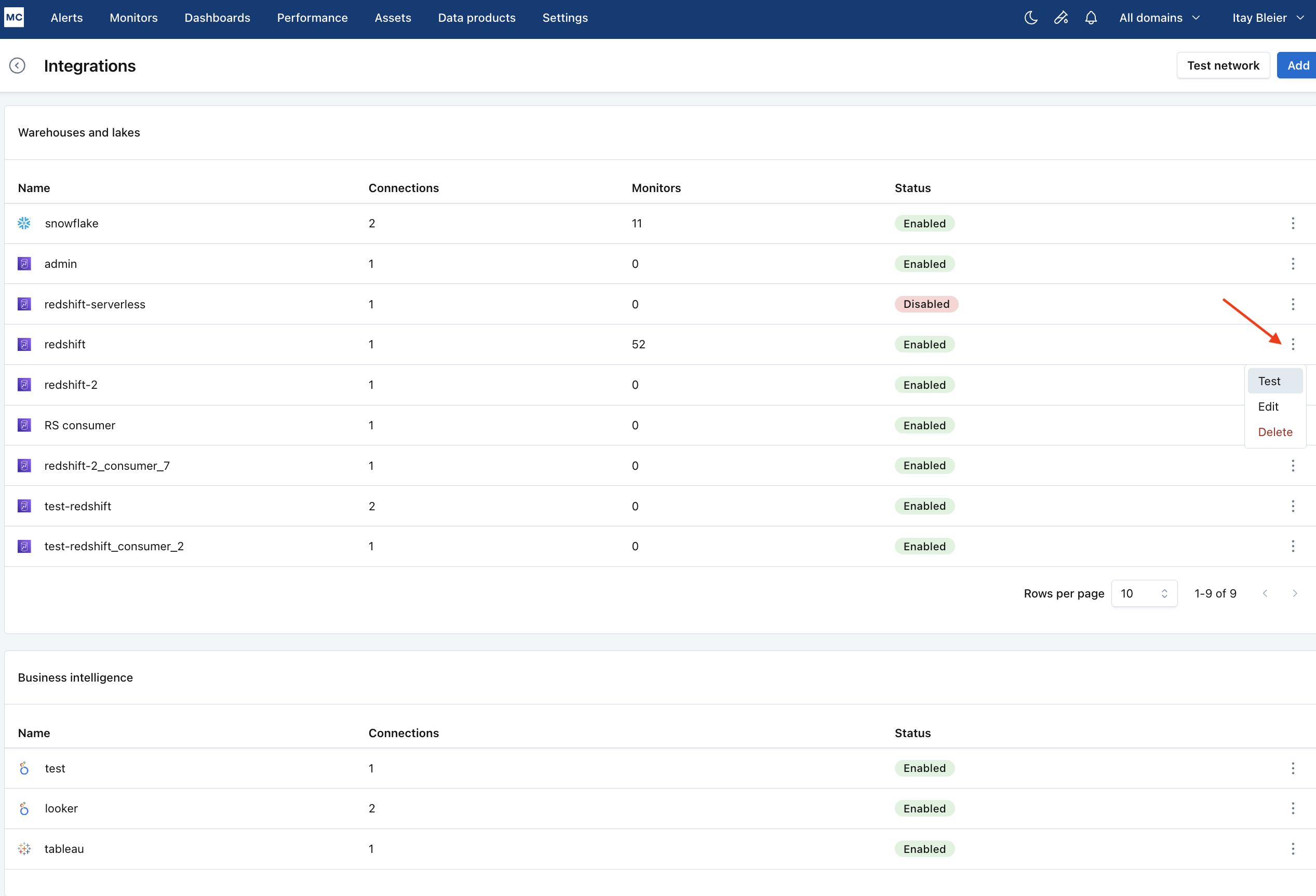
When running the validation test, you should see all green checkmarks. If any errors are encountered, the system will provide specific steps to resolve them.
If assets from a specific database or schema are missing you can use the Data Asset validation to test our ability to access them:
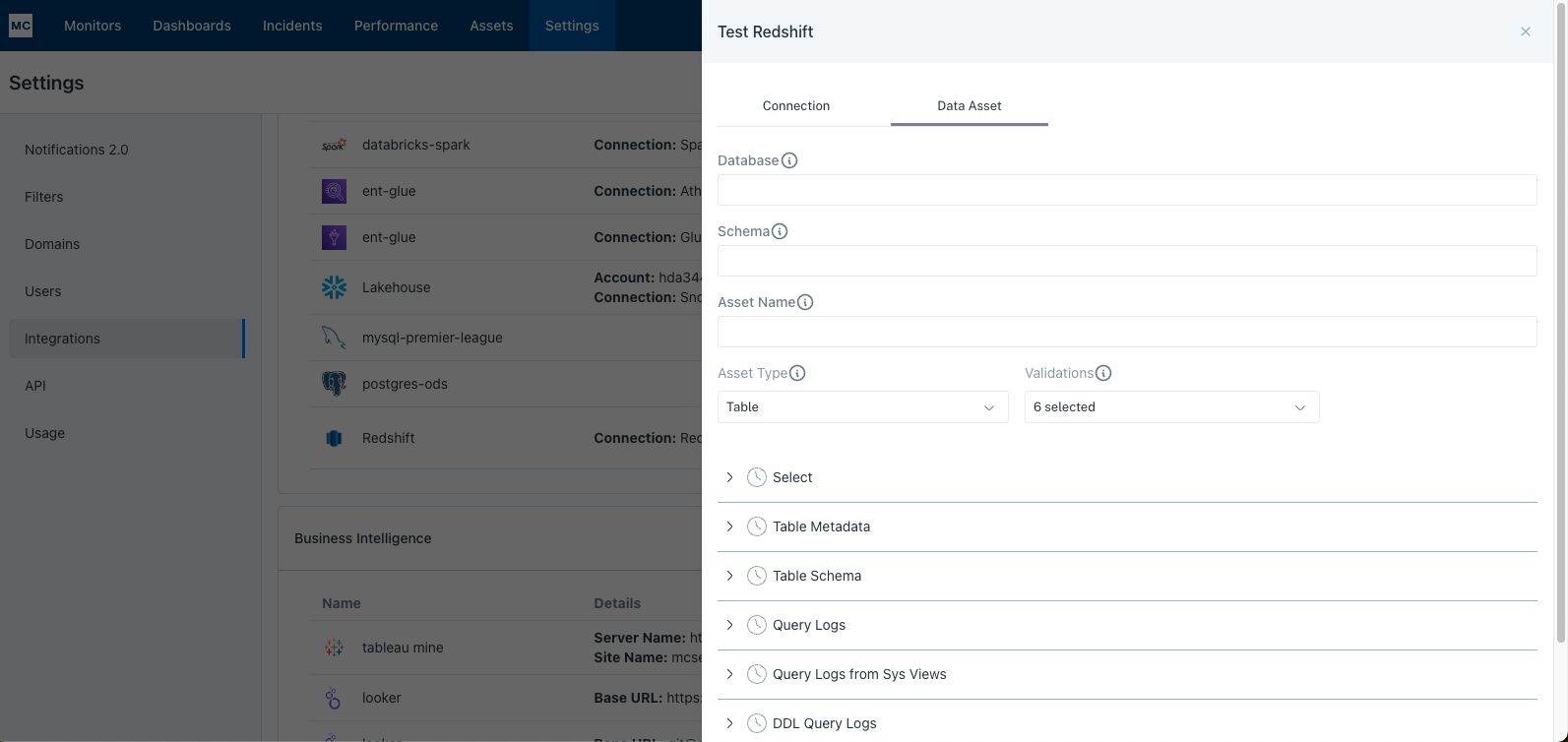
Note: Lineage can take up to 24 hours due to batching.
Updated 2 months ago