Tuning thresholds
As described in the overview, adjusting sensitivity and training data are the two ways for users to tune thresholds. These capabilities exist for Table (freshness, volume), Metric, and Custom SQL monitors.
Sensitivity
The most common way of tuning a threshold is to change a monitor's sensitivity. There are three different levels of sensitivity:
- Low: widens thresholds, resulting in fewer alerts.
- Medium: this is the default option when monitors are created.
- High: narrows ("tightens") thresholds, resulting in more alerts.
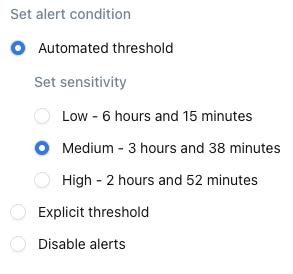
Sensitivity options for a freshness monitor
Training data
By adjusting training data, users can indicate which periods of time represent normal behavior for a particular metric (for example, the row count of a particular table). The anomaly detection models will then train on this data and produce thresholds, which can then be further widened or narrowed using sensitivity.
There are two key ways to manage which data is included in training models:
- Mark as normal: anomalies are automatically excluded from the set of data that trains models. When users review an alert, they can "mark as normal" for that anomaly to be added back into the set of training data. This will cause the threshold to widen, and similar anomalies will not be alerted to in the future.
- Select training data: by interacting with the chart of a monitor, users can exclude periods of data from training models. They can also use exclusion windows to define periods of time that should be ignored for an entire warehouse, database, schema, or table. These can be one-off or set for recurring holidays.
If an alert affects many different tables, users can also choose to 'Mark all as normal' without clicking through each event one-by-one. To do this, click the 'Tune model' dropdown and then 'Mark as normal', and a modal will appear with the option to Mark all as normal.
After taking either of these actions, it can take several hours before the new thresholds are visible.
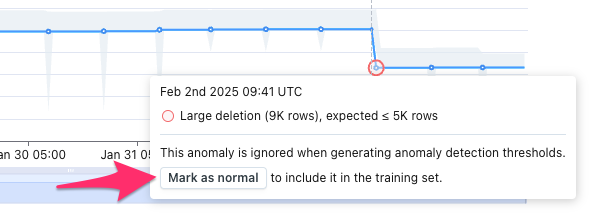
If users do not want to be alerted to similar anomalies in the future, they can "Mark as normal". The anomalous data point will then be re-introduced into the training set and thresholds will widen.
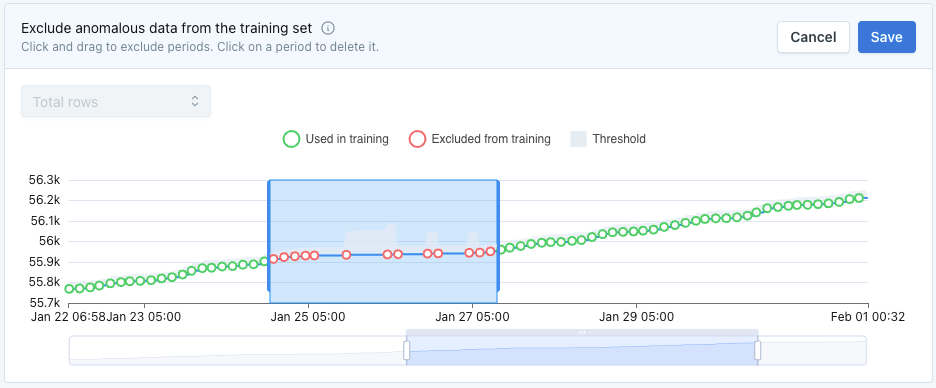
After click 'Select training data', users can define periods of time to exclude from training models. This gives users control to ensure bad data is not influencing thresholds.
Exceptions
To prevent repeated alerts, monitors are designed to recognize when a pattern that first appeared unusual is actually normal for your data. If the same type of anomaly occurs frequently enough, Monte Carlo may learn that this behavior is expected and automatically incorporate it into the normal baseline. When this happens, the alert threshold widens so the monitor no longer triggers on that recurring pattern. If this adjustment isn’t desired, you can revert it by unmarking the anomaly as normal to exclude it from training.
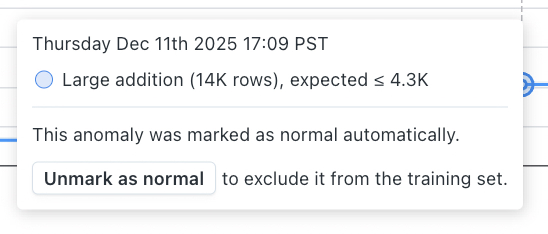
The number of repeated anomalies required for this learning to occur varies by monitor setup and data volume. As a general example, a daily Metric monitor usually needs to observe about 4 anomalous days within a 7-day period before treating the pattern as normal.
Updated about 1 month ago