Available Metrics
In Metric Monitors
All of the below metrics are supported by Metric Monitors. Users can also define custom metrics using SQL. The metric names for Monitors as Code (MaC) config are listed in the MaC Name column for each metric.
For the complete MaC YAML reference including all fields, schedules, and alert conditions, see Metric Monitor.
All metrics support either machine learning or manual absolute thresholds. The only exception are the Pipeline metrics listed below, where only machine learning thresholds are supported, and relative thresholds are not supported for metric monitors.
In Comparison Monitors
Most of the below metrics are supported by Comparison Monitors. However, Comparison Monitors do not support any of the (%) metrics, or Time since last change in row count.
Users can also define custom metrics using SQL. The metric names for Monitors as Code (MaC) config are listed in the MaC Name column for each metric.
Comparison Monitors only support manual thresholds.
Available Metrics
Pipeline
Metrics that detect freshness and volume anomalies. Often used withsegmentation. The traditional Pipeline Observability monitors do not support segmentation, so segmented freshness and volume monitoring are addressed through these metrics. Only machine learning thresholds are supported for these metrics.
| Metric | Description | MaC Name |
|---|---|---|
| Row count | Alerts to unusual spikes or drops in the count of rows | ROW_COUNT_CHANGE |
| Relative row count (%) | Alerts to unusual spikes or drops in the count of rows for a particular segment, relative to the overall number of rows (learn more) | RELATIVE_ROW_COUNT |
| Time since last change in row count | Alerts to unusually long periods of time since the last change in row count | TIME_SINCE_LAST_ROW_COUNT_CHANGE |
Uniqueness
Uniqueness metrics check for duplicates in unique keys like UUIDs, and for changes in cardinality.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| Unique (%) | Percentage of unique values across all rows | Numeric, String, Date | UNIQUE_RATE |
| Unique (count) | Count of unique values | Numeric, String, Date | UNIQUE_COUNT |
| Duplicate (count) | Count of duplicate values, calculated as the difference between the total number of rows with non-null values and total number of distinct non-null values | Numeric, String, Timestamp, Date, Time, Boolean | DUPLICATE_COUNT |
Completeness
Completeness metrics check for ways that data can be null or otherwise unpopulated.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| Null (%) | Percentage of rows where value is null | All | NULL_RATE |
| Null (count) | Count of rows with null value | All | NULL_COUNT |
| Non-null (count) | Count of rows with non-null value | All | NON_NULL_COUNT |
| Empty string (%) | Percentage of rows where the value is an empty string | String | EMPTY_STRING_RATE |
| Empty string (count) | Count of rows where the value is an empty string | String | EMPTY_STRING_COUNT |
| All spaces (%) | Percentage of rows where the text value is whitespace only | String | TEXT_ALL_SPACE_RATE |
| All spaces (count) | Count of rows where the text value is whitespace only | String | TEXT_ALL_SPACE_COUNT |
| NaN (%) | Percentage of rows with a value of NaN (Not a Number), meaning the value is undefined | Numeric | NAN_RATE |
| NaN (count) | Count of rows with a value of NaN (Not a Number), meaning the value is undefined | Numeric | NAN_COUNT |
| "none" or "null" (%) | Percentage of rows where the text value is a null keyword ("none", "null", "nil", "nothing" or "n/a") | String | TEXT_NULL_KEYWORD_RATE |
| "none" or "null" (count) | Count of rows where the text value is a null keyword ("none", "null", "nil", "nothing" or "n/a") | String | TEXT_NULL_KEYWORD_COUNT |
Distribution
Distribution metrics check for shifts in the numeric profile of data.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| Mean | Average value across all rows | Numeric | NUMERIC_MEAN |
| Median | Median value across all rows | Numeric | NUMERIC_MEDIAN |
| Min | Minimum value across all rows | Numeric | NUMERIC_MIN |
| Max | Maximum value across all rows | Numeric | NUMERIC_MAX |
| 20th percentile | 20th percentile of values | Numeric | PERCENTILE_20 |
| 40th percentile | 40th percentile of values | Numeric | PERCENTILE_40 |
| 60th percentile | 60th percentile of values | Numeric | PERCENTILE_60 |
| 80th percentile | 80th percentile of values | Numeric | PERCENTILE_80 |
| 95th percentile | 95th percentile of values | Numeric | PERCENTILE_95 |
| 99th percentile | 99th percentile of values | Numeric | PERCENTILE_99 |
| Zero (%) | Percentage rows with value equal to zero | Numeric | ZERO_RATE |
| Zero (count) | Count of rows with value equal to zero | Numeric | ZERO_COUNT |
| Negative (%) | Percentage of rows that have a negative value | Numeric | NEGATIVE_RATE |
| Negative (count) | Count of rows that have a negative value | Numeric | NEGATIVE_COUNT |
| Standard deviation | Standard deviation of values | Numeric | NUMERIC_STDDEV |
| Sum | Sum of values across all rows | Numeric | SUM |
| True (%) | Percentage of rows where the value is true | Boolean | TRUE_RATE |
| True (count) | Count of rows where the value is true | Boolean | TRUE_COUNT |
| False (%) | Percentage of rows where the value is false | Boolean | FALSE_RATE |
| False (count) | Count of rows where the value is false | Boolean | FALSE_COUNT |
Validity
Validity metrics check that values are honoring expected and usable formats, including common data entry errors.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| String length max | Maximum character length | String | TEXT_MAX_LENGTH |
| String length min | Minimum character length | String | TEXT_MIN_LENGTH |
| String length mean | Average character length | String | TEXT_MEAN_LENGTH |
| String length standard deviation | Standard deviation of character length | String | TEXT_STD_LENGTH |
| Integer (%) | Percentage of rows where the text value is an integer | String | TEXT_INT_RATE |
| Not integer (count) | Count of rows where the text value is not an integer | String | TEXT_NOT_INT_COUNT |
| Float (%) | Percentage of rows where the text value is a floating-point number | String | TEXT_NUMBER_RATE |
| Not float (count) | Count of rows where the text value is not a floating-point number | String | TEXT_NOT_NUMBER_COUNT |
| UUID (%) | Percentage of rows where the text value is a UUID (e.g., b391e7d2-80e0-4749-8c60-c76031c43dfe). The comparison is case insensitive. | String | TEXT_UUID_RATE |
| Not UUID (count) | Count of rows where the text value is not a UUID (e.g., b391e7d2-80e0-4749-8c60-c76031c43dfe). The comparison is case insensitive. | String | TEXT_NOT_UUID_COUNT |
| SSN (%) | Percentage of rows where the text value is formatted as Social Security Number from the United States (e.g., 123-45-6789) | String | TEXT_SSN_RATE |
| Not SSN (count) | Count of rows where the text value is not formatted as Social Security Number from the United States (e.g., 123-45-6789) | String | TEXT_NOT_SSN_COUNT |
| USA phone number (%) | Percentage of rows where the text value is a USA phone number (e.g., (123) 456-7890, +1 (123) 456-7890 etc) | String | TEXT_US_PHONE_RATE |
| Not USA phone number (count) | Count of rows where the text value is not a USA phone number (e.g., (123) 456-7890, +1 (123) 456-7890 etc) | String | TEXT_NOT_US_PHONE_COUNT |
| USA state code (%) | Percentage of rows where the text value is a two-letter USA state or territory abbreviation (e.g., TX) | String | TEXT_US_STATE_CODE_RATE |
| Not USA state code (count) | Count of rows where the text value is not a two-letter USA state or territory abbreviation (e.g., TX) | String | TEXT_NOT_US_STATE_CODE_COUNT |
| USA ZIP code (%) | Percentage of rows where the text value is a USA ZIP code format (e.g., 94109) | String | TEXT_US_ZIP_CODE_RATE |
| Not USA ZIP code (count) | Count of rows where the text value is not a USA ZIP code format (e.g., 94109) | String | TEXT_NOT_US_ZIP_CODE_COUNT |
| Email (%) | Percentage of rows where the text value is an email address (e.g., [email protected]) | String | TEXT_EMAIL_ADDRESS_RATE |
| Not email (Count) | Count of rows where the text value is not an email address (e.g., [email protected]) | String | TEXT_NOT_EMAIL_ADDRESS_COUNT |
| Timestamp (%) | Percentage of rows where the text value is an ISO-8601 format date or timestamp (e.g., 2023-01-12 16:50:11.045746 +00:00, 2023-01-12T16:50:11Z) | String | TEXT_TIMESTAMP_RATE |
| Not timestamp (count) | Count of rows where the text value is not an ISO-8601 format date or timestamp (e.g., 2023-01-12 16:50:11.045746 +00:00, 2023-01-12T16:50:11Z) | String | TEXT_NOT_TIMESTAMP_COUNT |
| In past (%) | Percentage of rows where the value is a date or time occurring before the time when the metric is evaluated, with a granularity of seconds used for comparison | Date | PAST_TIMESTAMP_RATE |
| In past (count) | Count of rows where the value is a date or time occurring before the time when the metric is evaluated, with a granularity of seconds used for comparison | Date | PAST_TIMESTAMP_COUNT |
| In future (%) | Percentage of rows where the value is a date or time occurring after the time when the metric is evaluated, with a granularity of seconds used for comparison | Date | FUTURE_TIMESTAMP_RATE |
| In future (count) | Count of rows where the value is a date or time occurring after the time when the metric is evaluated, with a granularity of seconds used for comparison | Date | FUTURE_TIMESTAMP_COUNT |
| Unix time 0 (%) | Percentage of rows where the value is Unix time 0 | Date | UNIX_ZERO_RATE |
| Unix time 0 (count) | Count of rows where the value is Unix time 0 | Date | UNIX_ZERO_COUNT |
ML Metrics
Use ML metrics to monitor model performance and data quality.
ML Regression Performance
Measures how far off a model's predictions are from actual values. Use these metrics to track prediction accuracy on continuous/numeric outputs — like forecasted revenue vs. actual revenue, or predicted scores vs. observed scores. Both columns must be numeric.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| RMSE | Square root of the average squared difference between predicted and actual values | Numeric | RMSE |
| MAE | Average absolute difference between predicted and actual values | Numeric | MAE |
| MAPE | Average percentage difference between predicted and actual values | Numeric | MAPE |
| R-Squared | How closely predictions match actual values, on a scale | Numeric | R_SQUARED |
| Mean Error | Average difference between predicted and actual values — positive means overpredicting, negative means underpredicting | Numeric | MEAN_ERROR |
ML Classification Performance
Measures how often a model predicts the correct category or label. Both columns must be the same data type. Decimal/float columns are not supported — use regression metrics for continuous values.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| Accuracy | How often the predicted value matches the actual value, as a percentage | String, Boolean, Integer | ACCURACY |
ML Drift Detection
Detects when a column's data distribution shifts over time. Use drift metrics to catch upstream data changes or concept drift in model inputs and outputs.
Drift metrics compare recent data against a configurable baseline period — either a rolling window (default: 14 days) or a fixed date range. For numeric columns, data is discretized into equal-width bins (default: 10); more bins capture finer distribution changes, fewer bins are more tolerant of noise. For categorical columns (string and boolean), each distinct value acts as its own bin. The number of bins and baseline period are both configurable in the alert condition builder.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| PSI | How much a column's distribution has shifted from baseline, as a score | Any | PSI |
| KS Test | Maximum difference between two cumulative distributions, as a score | Numeric | KS_TEST |
| JS Divergence | Symmetric difference between two probability distributions, as a score | Any | JS_DIVERGENCE |
ML Cardinality
Tracks changes in the set of unique values in a column over time. Use cardinality metrics to detect new categories appearing in production or expected values dropping out.
Cardinality metrics compare recent data against a baseline period, which can be configured as a rolling window (e.g., 14 days) or a fixed date range.
| Metric | Description | Column Types | MaC Name |
|---|---|---|---|
| New Values | Count of distinct values present in the current period but not in the baseline | Any | NEW_VALUES |
| Missing Values | Count of distinct values present in the baseline but not in the current period | Any | MISSING_VALUES |
Relative row count
Relative row count will alert to sudden shifts in the distribution of categorical fields. It tracks the percentage of rows in a given segment compared to the overall number of rows, and alerts when the percentage for a segment suddenly spikes higher or drops lower. Because of this, segmentation is required when using this metric. Common examples:
- An
eventstable has anapp_versionfield. The user would like to be alerted if anyapp_versionis suddenly receiving a disproportionately high or low number of rows relative to overall volume, as it may indicate issues with that version. - An
orderstable has acountryfield. The user would like to be alerted if anycountryis suddenly receiving a disproportionately high or low number of rows relative to overall volume, as it may indicate an issue with processing order from that country.
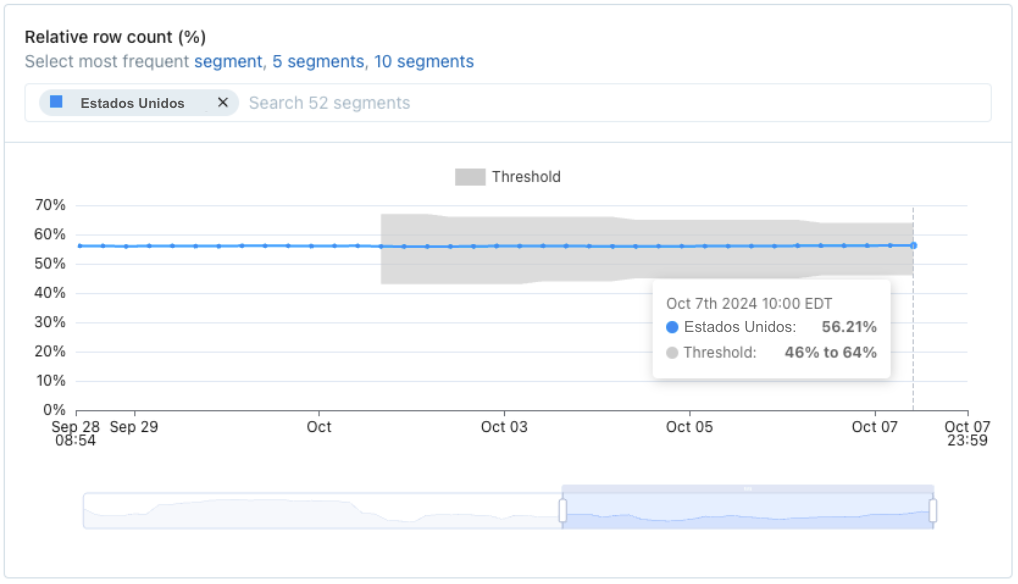
Relative row count can also alert when new segments appear, so long as they represent a significant shift in the distribution of rows. However, to always alert when any new segment appears, we recommend configuring a Validation monitor with the is not in set operator.
Relative row count was formerly its own monitor type called Dimension Tracking. Starting in October 2024, Dimension Tracking monitors could no longer be created through the UI and users were guided to use relative row count instead.
Updated 25 days ago