dbt Integration
What is dbt?
dbt (data build tool) is a tool that enables data analysts and engineers to transform data in their warehouses more effectively. It is the t (transform) in ELT (Extract, Load, Transform).
dbt lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation.
dbt comes in two flavors. dbt Core is an open source command line tool where scheduling jobs relies on external tools like Airflow, CI or Github. dbt Cloud is a managed service that allows more advanced scheduling right from the web UI. Both Core and Cloud are supported by Monte Carlo.
Why connect dbt to Monte Carlo?
Monte Carlo centralizes context on dbt jobs, models and their associated tables on a single pane of glass. dbt context is overlaid on lineage graph to help you troubleshoot issues and evaluate impact of failures. Simply toggle on "show dbt status" to see latest model run status and timestamps. Error statuses will show by default without toggling needed.
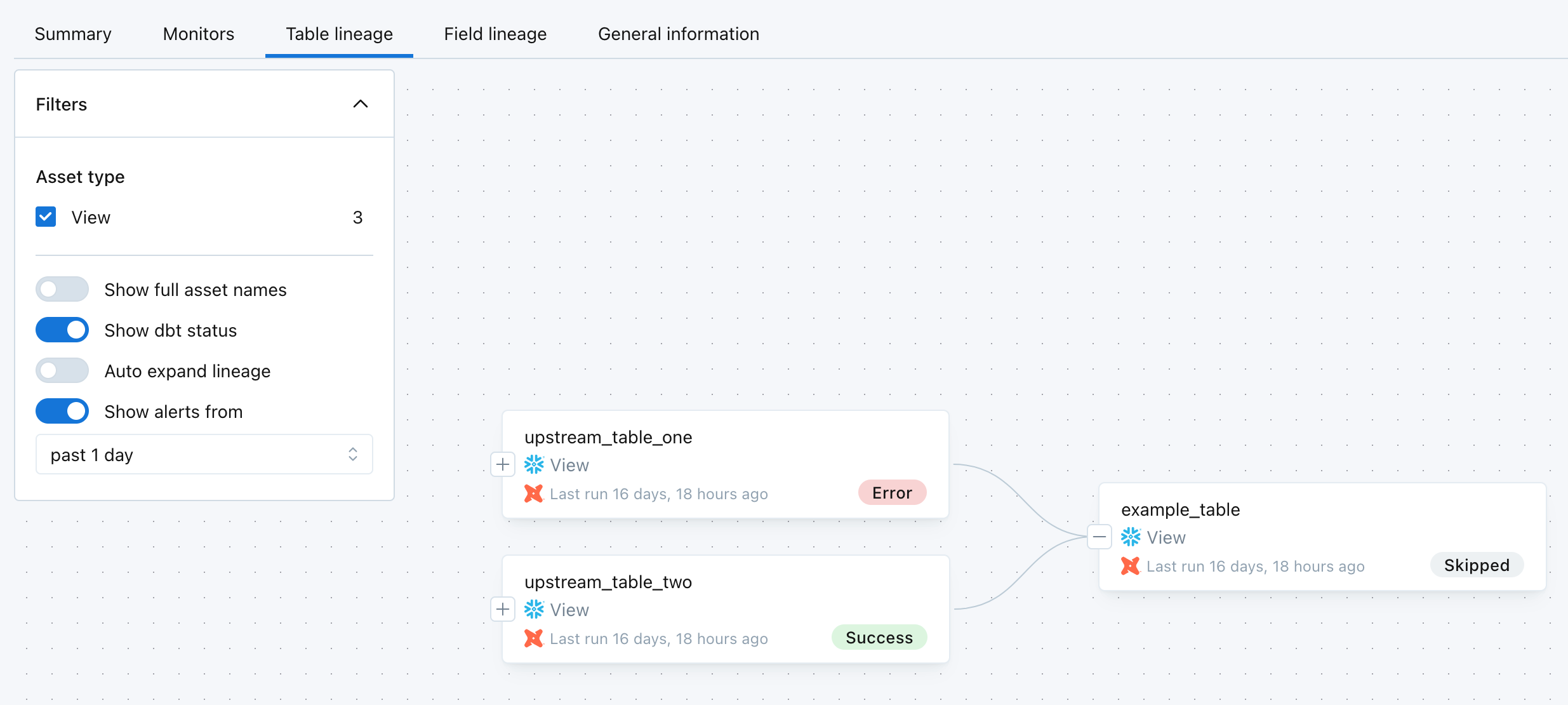
Note: Monte Carlo displays dbt jobs on lineage edges only when a downstream table is updated by a dbt job that explicitly references an upstream table. This requires:
- Source-Target Relationship: The dbt job must include at least one source() or ref() reference to the upstream table.
- Job Execution Across Dependencies: If the dbt job is configured to update only a single model (e.g., dbt run --select
<model>), lineage edges may not appear unless the upstream model is also built in the same job run.
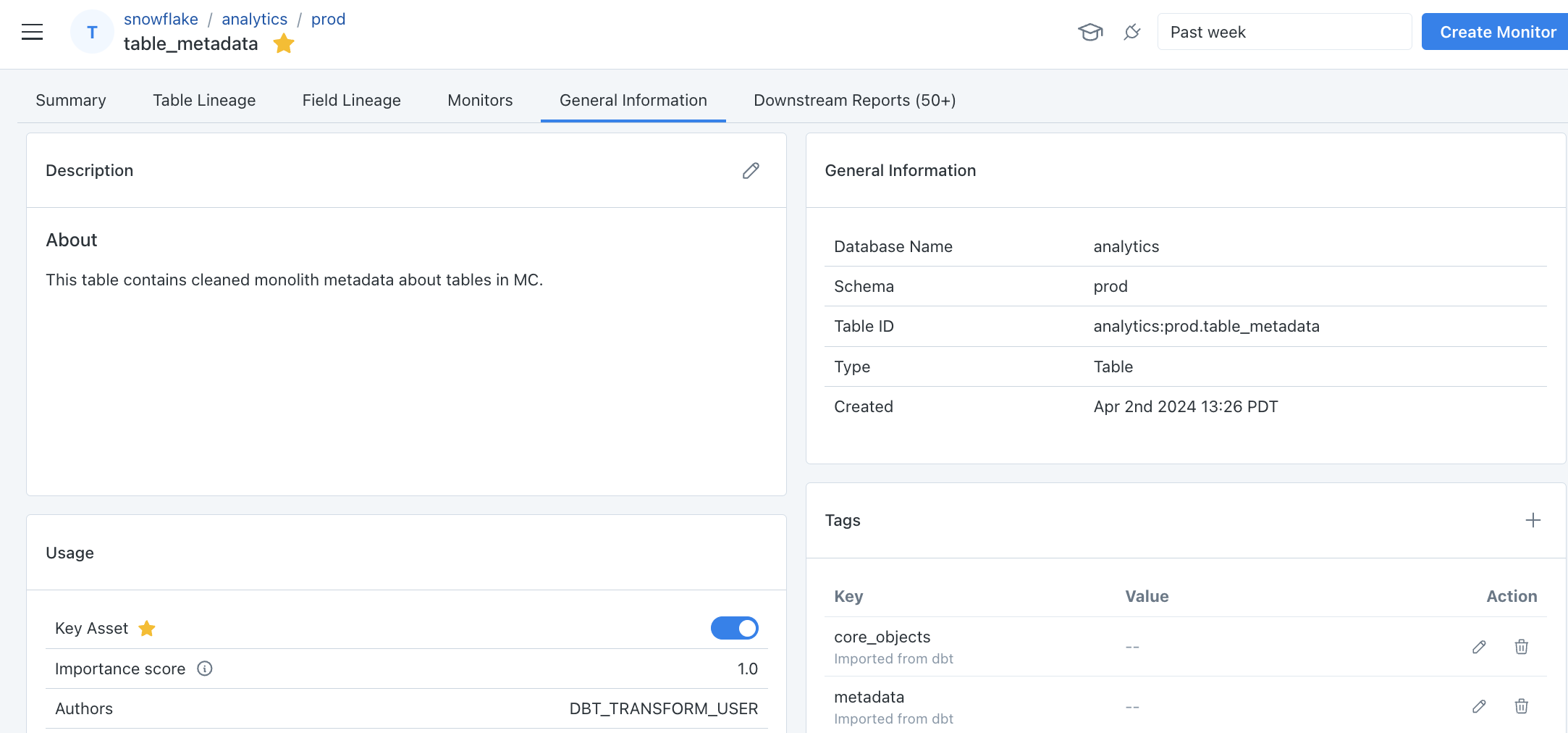
Tags, descriptions, and meta configs are imported from dbt. Model tags can also be imported as asset tags on the parent dbt job via project-level opt-in, in the dbt integration settings. See Asset tags → dbt Tags.
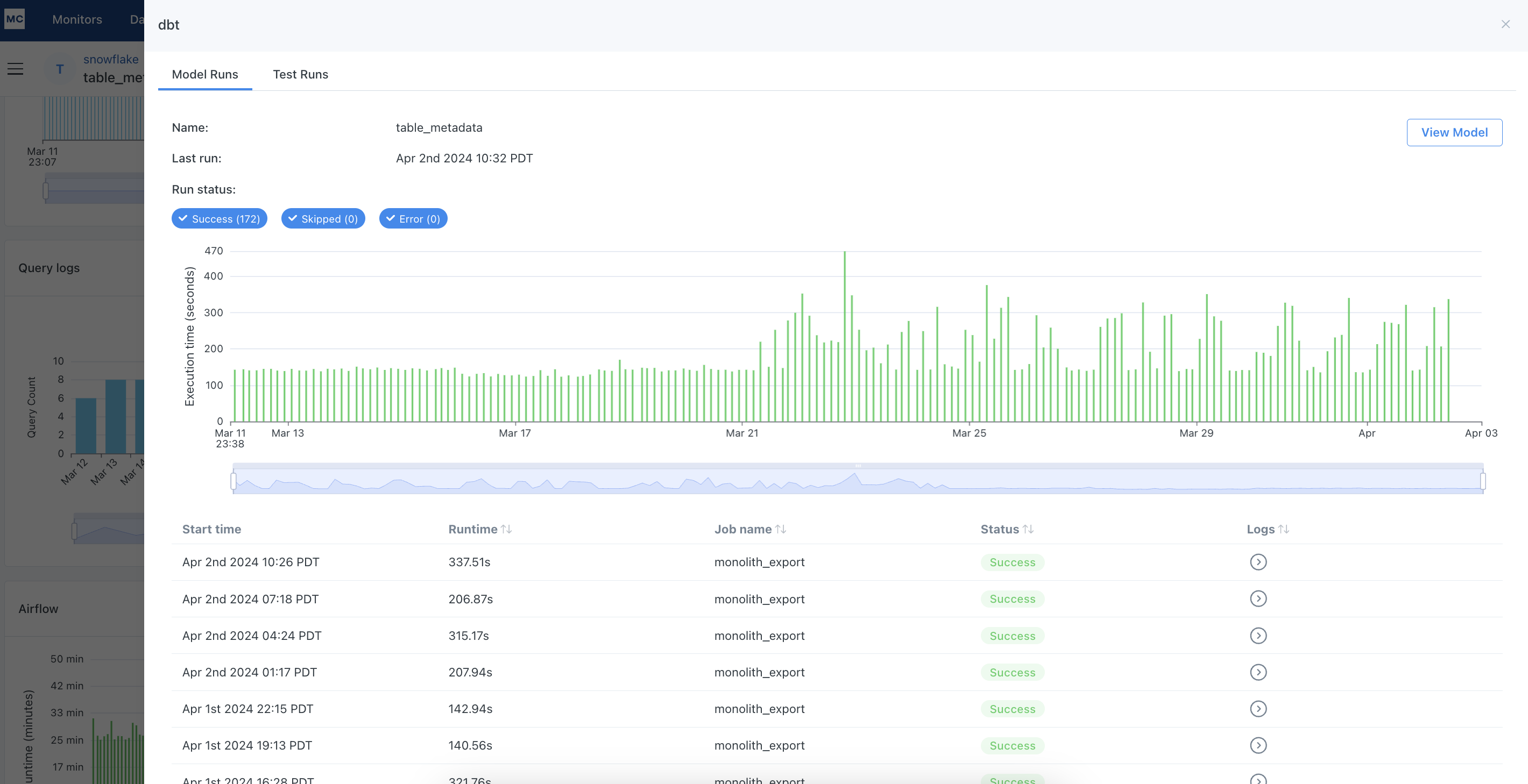
Here you can see an overview of the model. Clicking the "View Model" in the upper right corner will display the SQL that defines it. We can also see a run history of the model. The graph visualizes the execution time of mode runs from the time period selected for the assets page. You can filter the runs based on run statuses: success, error, skipped. You also can toggle to the "Test Runs" tab to see an overview of dbt tests defined for the model, as well as a similar run history for all the tests.
You can also leverage this integration to centralize all data incidents, including dbt model errors and test failures, in one place. Monte Carlo allows you to generate incidents based on dbt model errors and test errors . You can detect, triage, investigate, and analyze dbt failures all within Monte Carlo.
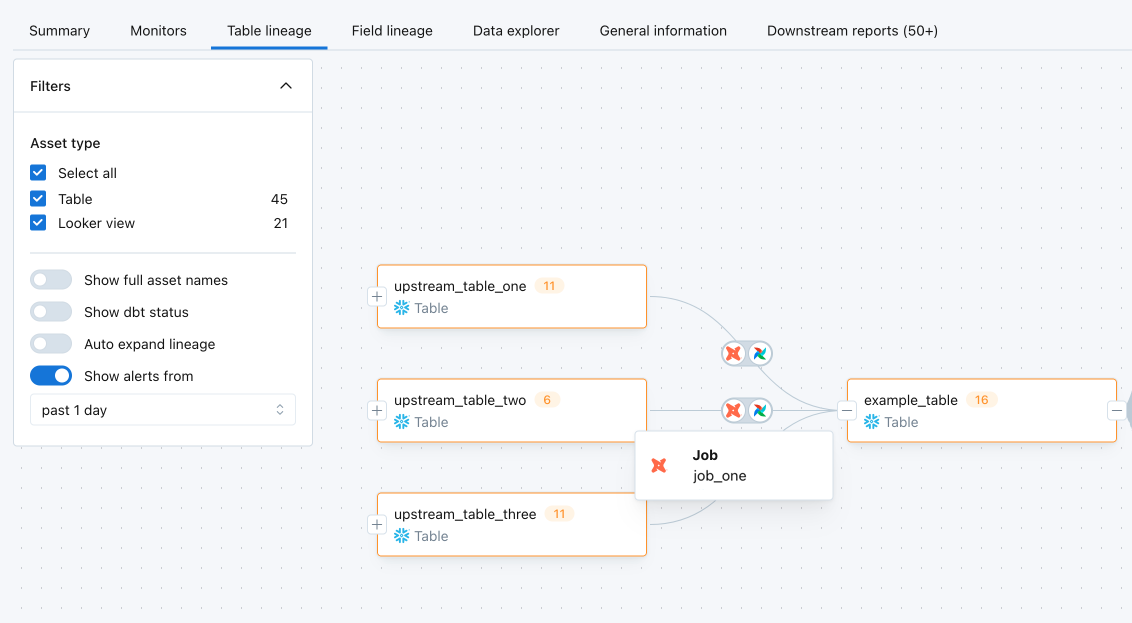
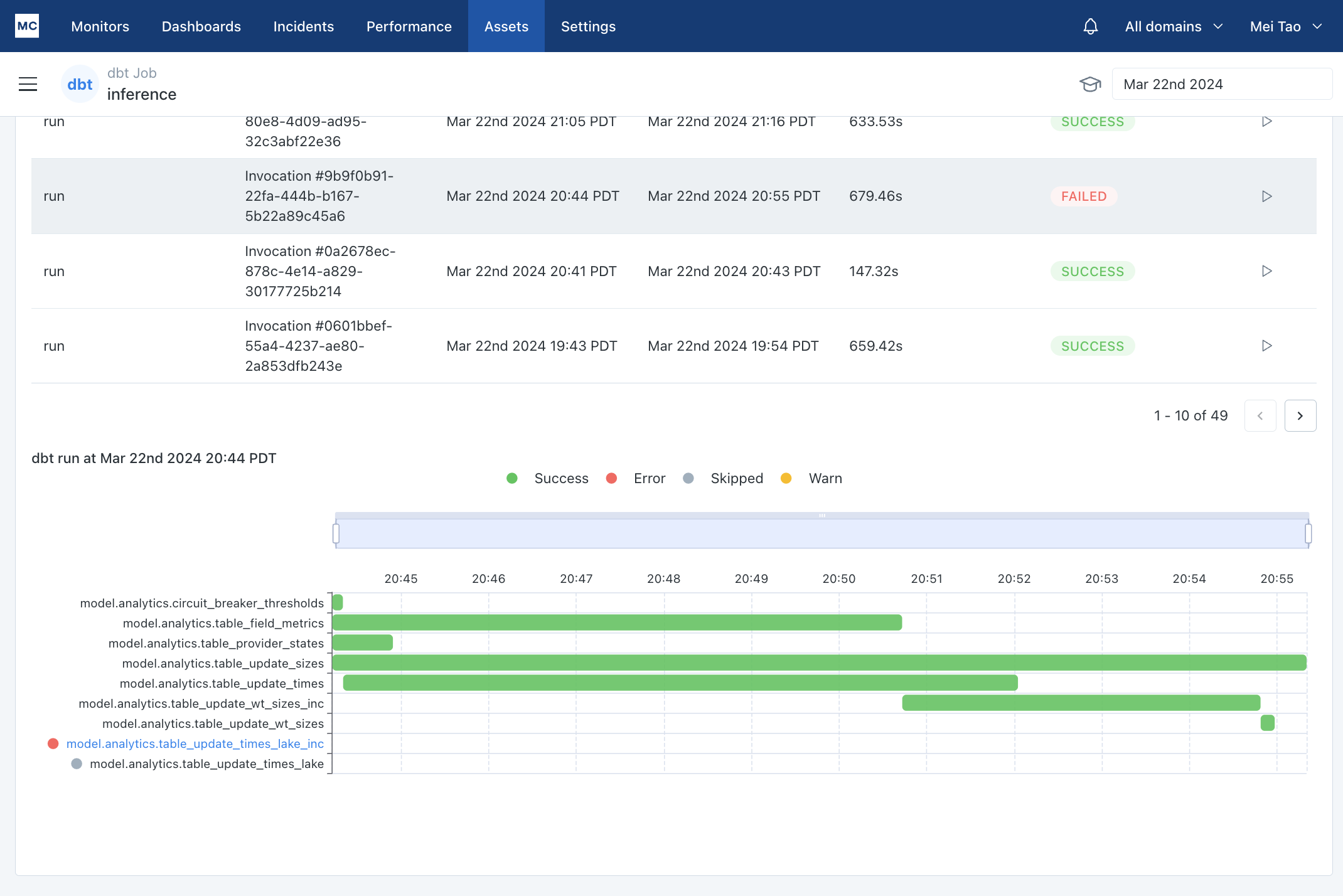
 Clicking on "Investigate Job" will land you on a job's view in Assets. You can analyze a dbt run in a waterfall view that allows you to easily identify bottlenecks, so you can quickly determine whether you need to optimize a model.
Clicking on "Investigate Job" will land you on a job's view in Assets. You can analyze a dbt run in a waterfall view that allows you to easily identify bottlenecks, so you can quickly determine whether you need to optimize a model.
Setting Up dbt
The following guide explains how to set up the integration.If you are using dbt Core, this guide will help you through set up. We are able to build our dbt Core integration into most existing CI/CD pipelines with pycarlo as well as Airflow.
If you are using dbt Cloud, this guide will help you through set up.
How can I validate Monte Carlo has access to my assets?
After completing the dbt integration setup, your dbt assets should appear in the Monte Carlo Assets page within 1 to 5 hours. If you don't see your assets after this time period, you can reach out via our Support Agent.
Note: Lineage can take up to 24 hours due to batching.
FAQs
On the Jobs Performance page, why does my "default-job" dbt job take a long time to load?
"default-job" is the default job name MC assigns to your dbt core job runs if you did not provide dbt job names in your configuration. This results in a single dbt job that includes a large number of models, tests, snapshots, and seeds—usually more than 200. As everything is bundled into one job, it becomes difficult to efficiently calculate performance metrics like historical trends, average run times, and error counts for each component.
To improve performance and visibility, we recommend breaking up your dbt "default-job" into smaller, more focused jobs via providing unique job names for your dbt commands. This helps Monte Carlo process and display job metrics much more efficiently.
I’m encountering a CA certificate error when running MC-dbt.
CA certificate errors indicate a problem with the customer’s local execution environment (such as missing, expired, or misconfigured root or intermediate certificates in the OS or Python trust store). MC-dbt relies on the system’s certificate chain for TLS verification and does not manage or override certificate configuration. These errors must be resolved by updating the local environment and are not caused by Monte Carlo.
Updated 3 months ago