Exclusion Windows
Occasionally, an undesirable gap may form in Monte Carlo's history of metadata and metrics for your tables. This is often the result of a service provider outage, or an integration issue between Monte Carlo and your data sources. These gaps are undesirable because they can reduce the sensitivity of Monte Carlo's anomaly detection.
In addition, it often makes sense to add exclusion windows for Holidays, if you expect the amount or the profile of data to be dramatically different on those days.
Exclusion windows allow you to exclude these periods of time from the history that trains the machine-learning thresholds in Monte Carlo. When applied proactively, it also prevents many types of alerts from being triggered.
Setting up exclusion windows
In Settings > Exclusion windows, you can add an exclusion window to proactively counteract the effects of this issue. When an exclusion window is created, the specified timeframe is removed from the training data that informs Monte Carlo's anomaly detection. This is applied for the detectors that trigger anomalies for:
- Automated freshness monitoring
- Automated volume monitoring
- Metric Monitors with automated thresholds
Note:
- Exclusion Windows do not apply to the automated threshold for SQL Rules. SQL Rules will typically fail to execute in the circumstances described above, so there are no results from those timeframes to inform the anomaly detection anyway.
- Exclusion Windows can take up to 9 hours to be incorporated into the training data
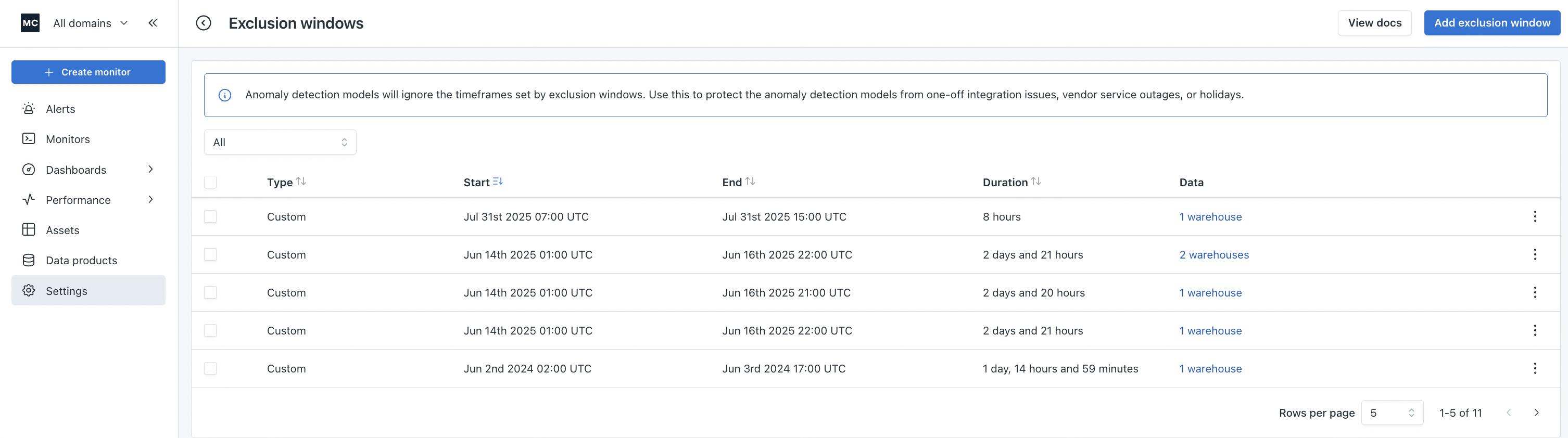
Exclusion windows are managed from Settings > Exclusion windows
When creating an exclusion window, you can apply it to either:
- An entire warehouse or source. If you only have one data source, this is akin to applying the exclusion window globally.
- Specific projects
- Specific datasets
- Specific tables
Exclusion windows are most frequently applied after the issue that introduced the gap is resolved. However, they can also be applied while the issue is ongoing (in which case you'd need to guess the end time). And they can also be added for the future, typically to protect against gaps introduced by planned maintenance or downtime of your pipelines.
If an exclusion window is created for an ongoing issue or a future issue, no incidents or notifications from the above detectors will be generated for the duration of the exclusion window.
On the Assets page, exclusion windows are represented on the freshness and volume graphs using a crosshatch pattern.
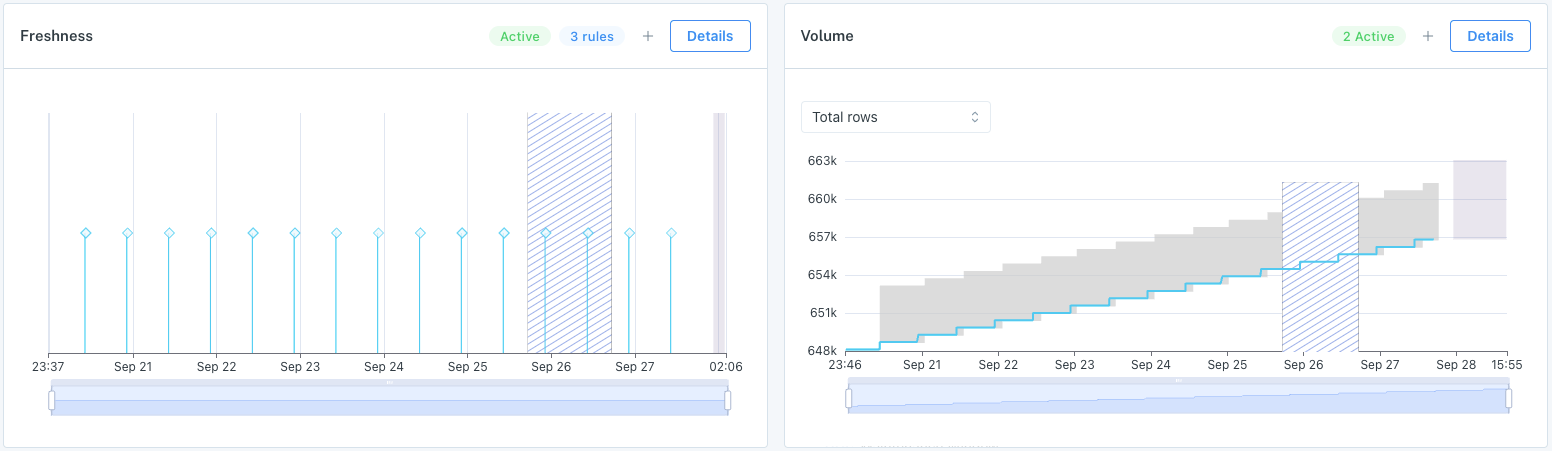
Crosshatching on freshness and volume charts indicates the area of an exclusion window.
Some example use cases could be:
- You performed a large backfill, which you do not want to affect volume training.
- There was a collection or permissions issues which caused metadata not to be collected or collected sparsely, which you do not want to affect freshness training.
- A large amount of NULLs accidentally entered a table and were removed, and you do not want it to affect monitor training.
- You are going to be doing maintenance and want Monte Carlo to know ahead of time.
Updated about 1 month ago