Migrating the Databricks Metadata Job to a Job Cluster
- In your Databricks Workspace, go to the Workflows pane.
- Click the Monte Carlo Job - it should be prefixed with
monte-carlo-metadata-collection

- On the right pane, under Compute, click the Swap button.
- In the pop-up box, click New job cluster.
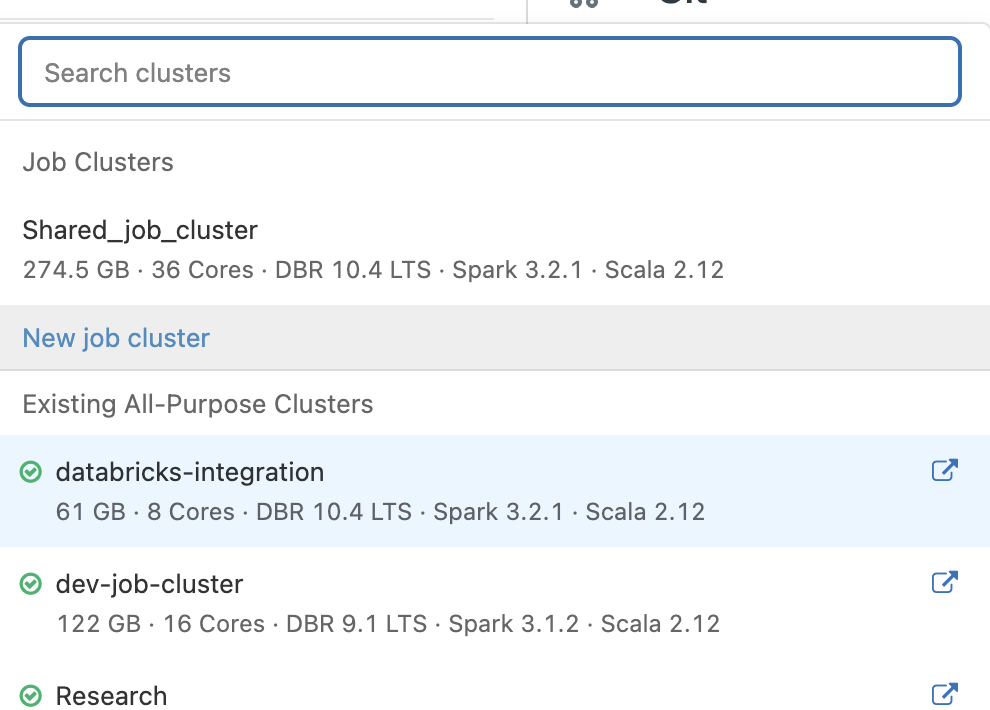
-
Create the job cluster with your desired settings. If you prefer the most inexpensive recommendations, see below. If the job is taking too long at these settings, we can up the cluster size or number of workers.
-
Nodes: Single node
-
Node type: i4i.large (cheapest AWS cluster available)
-
Important 🚨: Under Advanced options, on the Spark tab, append these two arguments under Spark config:
spark.databricks.clusterSource API spark.databricks.hive.metastore.client.pool.size 40 spark.databricks.isv.product MonteCarlo+ObservabilityPlatform
-
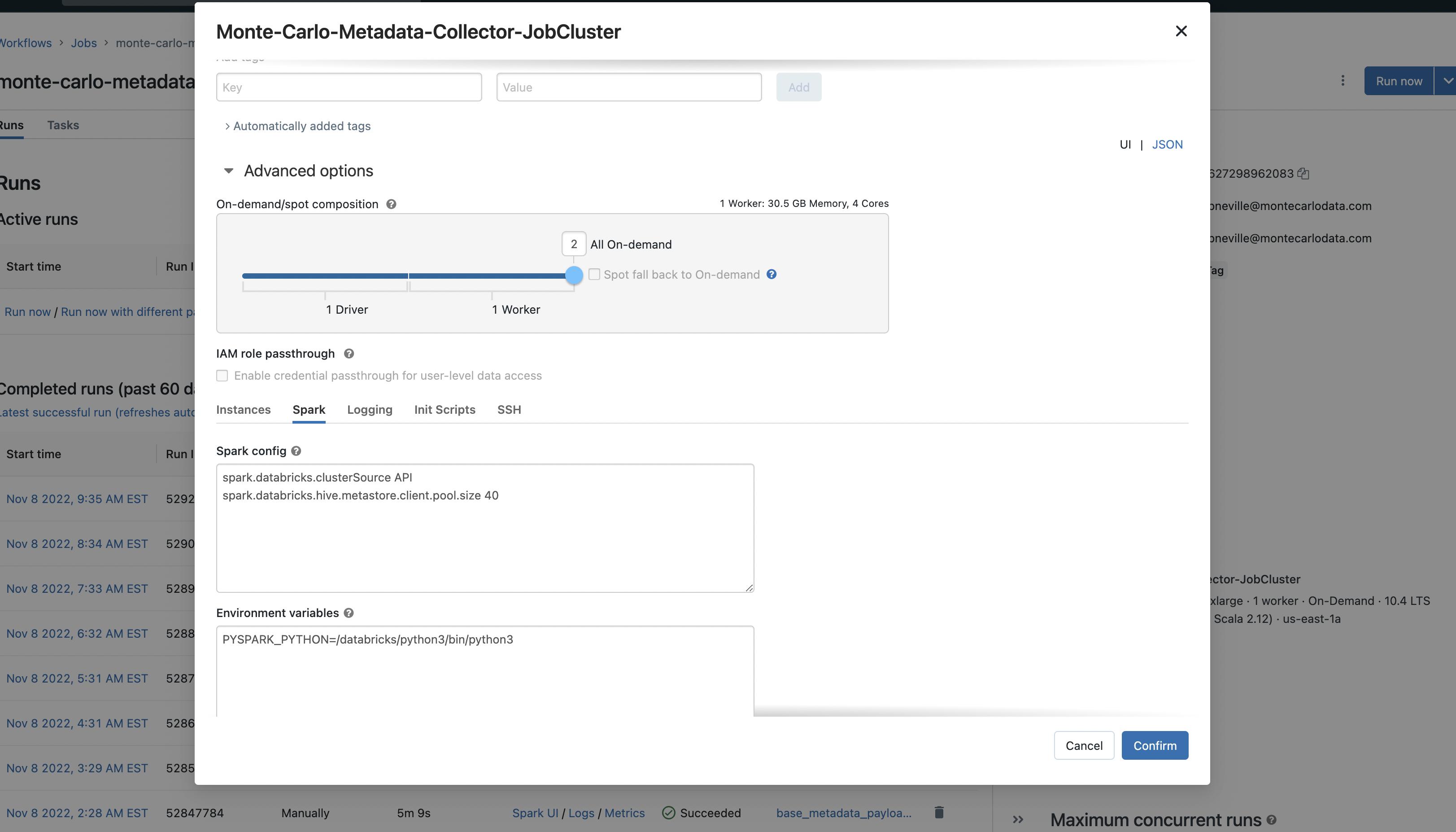
- Click Confirm and then Update.
- Under Permissions, make sure the Service Principal or User (for Personal Access Token) is selected as
Is Owner. - Verify that the job is able to run with the permissions available.
- Run the following command with the montecarlo cli
-
montecarlo integrations update --connection-id <connection_id> --changes '{"uses_job_cluster": true}'
-
Updated 9 months ago