Redshift Datashares
Minimum DC VersionYour data collector must have a minimum of 22381 to support Redshift Datashares
I. Redshift Datashares in Monte Carlo
What are Redshift Datashares?
Redshift datashares allow you to share data between different Redshift clusters or accounts without copying the data. This is useful for:
- Sharing data with partners or customers
- Centralizing data in one cluster and sharing subsets with other clusters
- Enabling data mesh architectures
For more information about Redshift datashares, see the AWS documentation.
Datashare Concepts
Datashares have two key concepts: Producers and Consumers.
Producers
The producer is the Redshift cluster or account that owns and shares the data. Think of it as the "data source" or "data owner."
Producer Characteristics:
- Data owner: the cluster that contains the original data
- Share creator: creates and manages the datashare
- Access grantor: controls what data is shared and with whom
- Source of truth: the authoritative copy of the data
Producer Responsibilities:
- Create datashares and define what data to share
- Grant access to specific consumers
- Manage permissions and control what operations consumers can perform
- Maintain data and keep shared data up-to-date and accurate
Consumers
The consumer is the Redshift cluster or account that receives access to the shared data. Think of it as the "data recipient" or "data user."
Consumer characteristics:
- Data recipient: the cluster that accesses shared data
- Share user: uses the datashare created by the producer
- Read access: can query the shared data (typically read-only)
- Dependent: relies on the producer for data updates
Consumer Responsibilities:
- Accept shares and connect to the datashare provided by the producer
- Query data and use the shared data for analysis or reporting
- Respect permissions and follow the access controls set by the producer
- Monitor dependencies and track when shared data is updated
Important Note: Tables in consumer databases typically do not contain size and freshness metadata. Monte Carlo handles this by collecting and propagating metadata from producer tables to consumer tables.
II. Setting Up Redshift Datashares in Monte Carlo
Connection Setup
Since producer and consumer databases are separate (and generally in separate accounts), Monte Carlo requires separate connections for each producer and consumer database. In the UI, these are displayed as separate connections within an integration, but they are logically connected as producer and consumer.
This separation is necessary because producer and consumer tables might share the same database name, which would create conflicts if they were in the same warehouse connection.
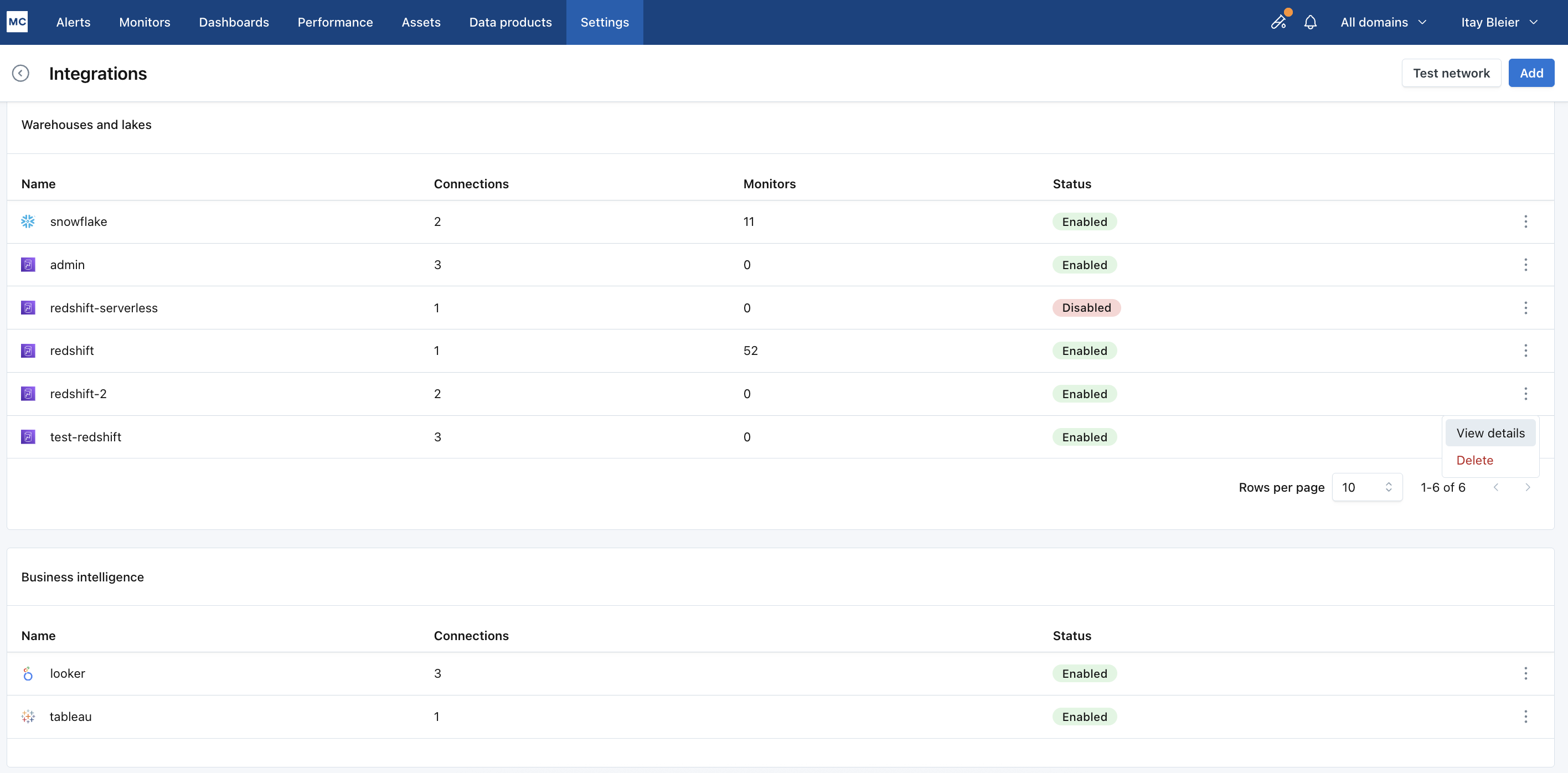
Adding a Consumer Connection
-
Navigate to the Producer Connection: Click on "View details" for the producer connection in your Monte Carlo integration.
-
Add new connection: Click the "Add" button to add a new connection.
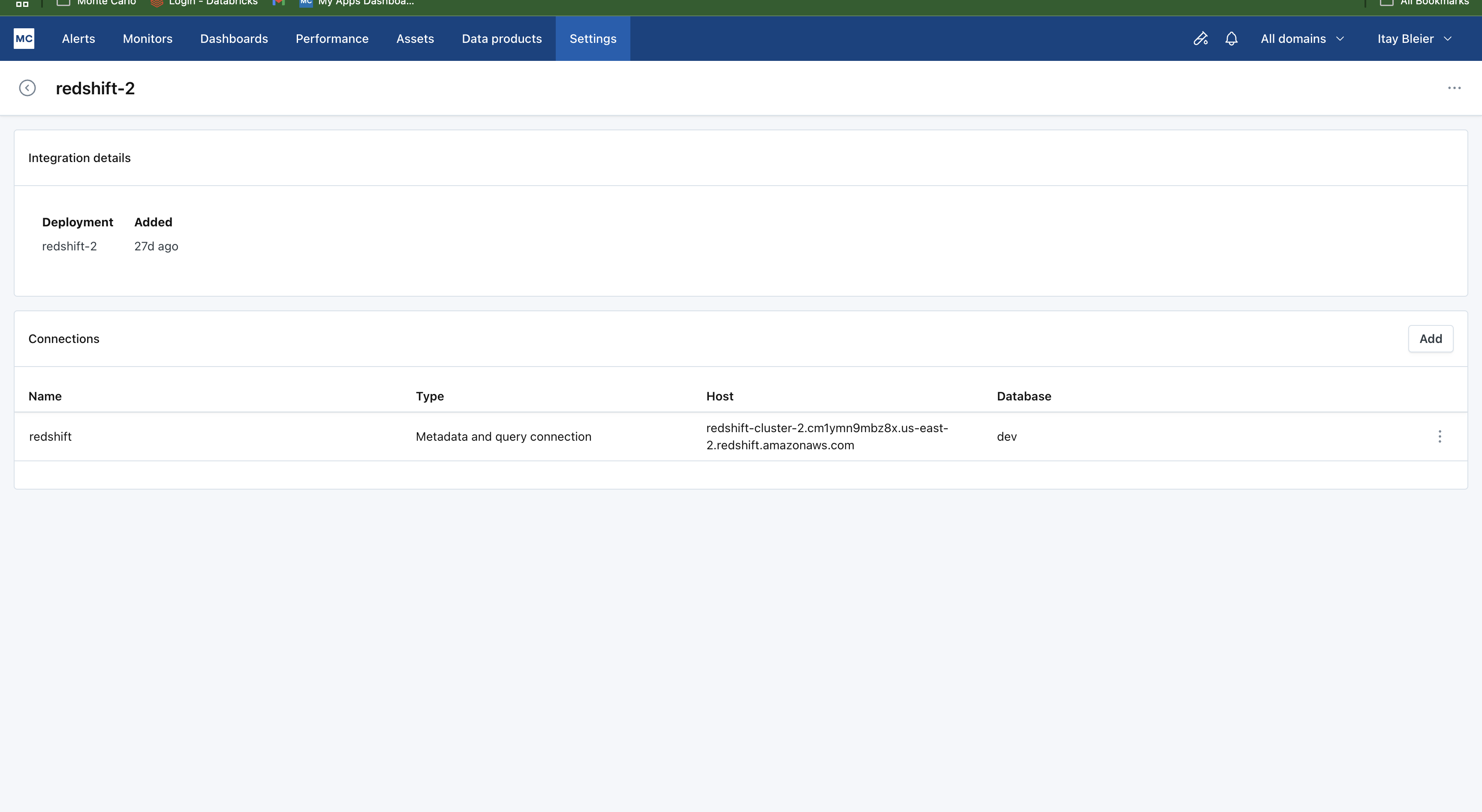
- Select Consumer cluster: Choose Consumer cluster connection from the connection type options.
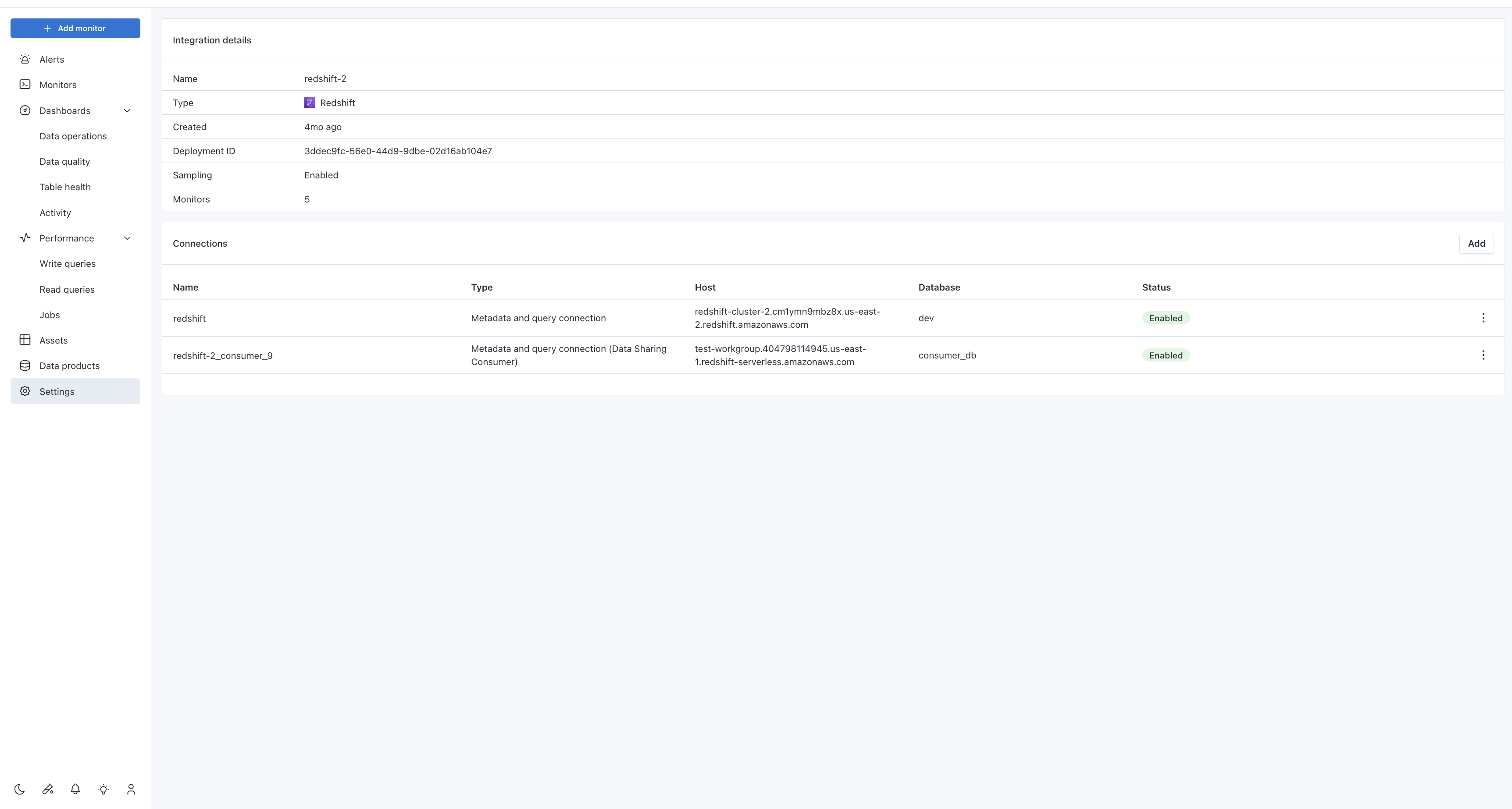
- Configure connection: Create the consumer connection as you would any other Redshift connection, using the consumer cluster's credentials and connection details.
- Verify setup: The consumer connection will appear in the connection details page alongside the producer connection.
III. How Monte Carlo Handles Datashares
Data Collection
Tables Queried on Customer Side
Monte Carlo queries the following Redshift system views to collect datashare information:
svv_all_tables: Basic table and view informationsvv_all_columns: Column-level schema information
These queries are run with the same permissions as your existing Redshift integration, so no additional permissions are required beyond what's needed for standard Monte Carlo data collection.
Lineage
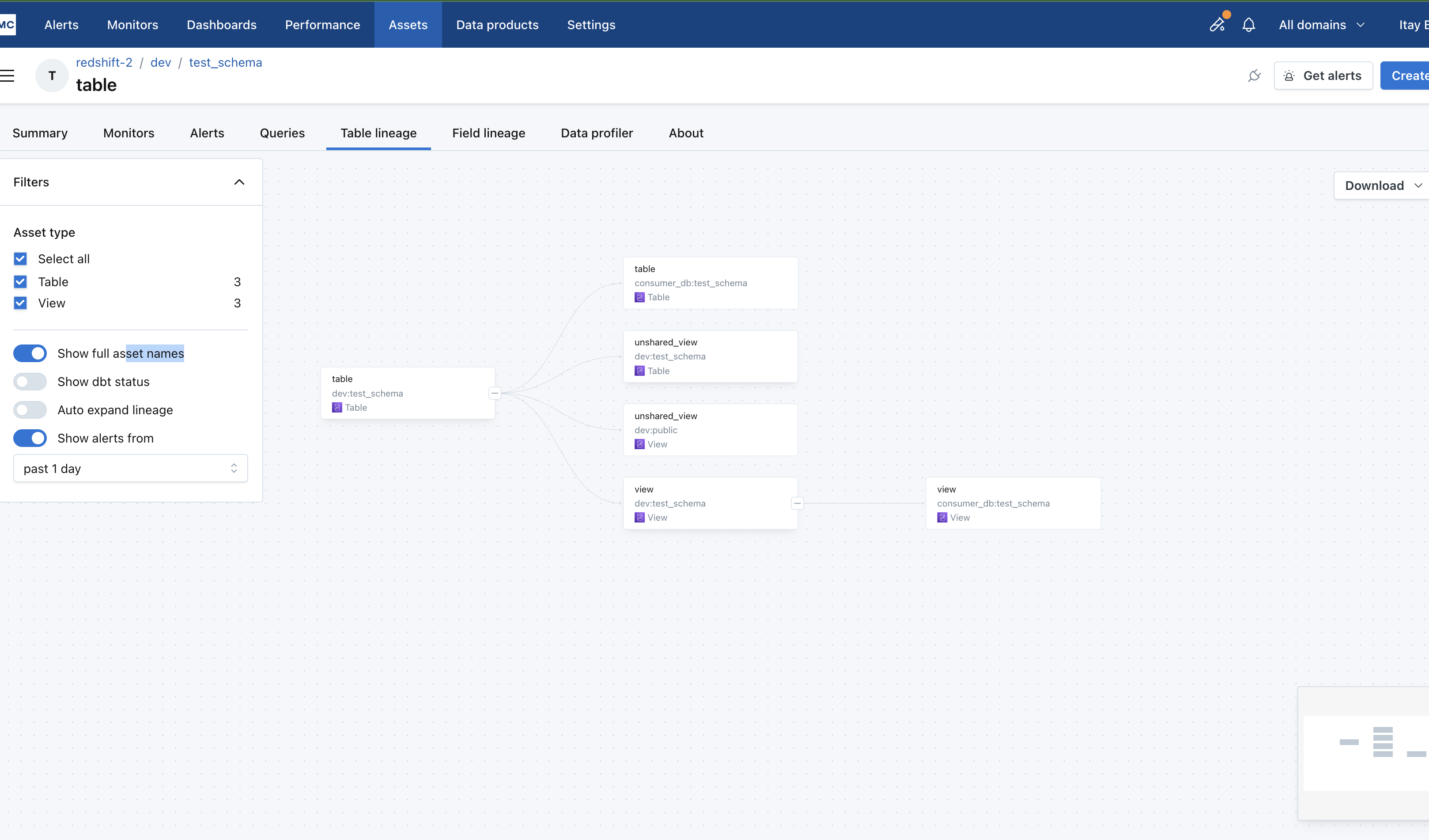
Monte Carlo automatically establishes downstream lineage connections between producer and consumer tables in datashares. When you view lineage for either a producer or consumer table, you'll see the connections to their corresponding tables across the datashare relationship.
Example of Downstream Directional Producer Consumer Lineage.
Monitoring Behavior
Out-of-the-Box Monitors
Since producer and consumer tables contain the same data and have identical metadata, Monte Carlo only supports out-of-the-box volume and freshness monitors on producer tables. This prevents:
- Double alerting on the same data
- Conflicting models between producer and consumer tables
- Potential confusion from monitoring the same data in two places
Custom Monitors
If you want to set up alerts on consumer tables, you can create custom monitors. However, all monitors on consumer tables will be explicitly set to avoid the issues mentioned above.
Updated 10 months ago