Validation Monitors
Validation monitors help to identify rows in your tables with bad data ("invalid rows"). They make it easy for users with limited or no SQL knowledge to set up alert conditions on specific fields or a combination of fields. For example, to validate that strings are formatted correctly, timestamps are not in the future, and numerical values are not negative.
To configure validation monitors as code, see the Validation Monitor MaC reference.
Users can choose from a rich library of operators and templated alert conditions, or create their own using custom SQL. See Available Conditions for a full list of operators and templated conditions.
Creating Validation Monitors
Validation monitors can be created from the Create Monitor page or Assets page. Configuration steps include:
1. Choose Data
Users have two options to choose data from.
-
Select a table or view:
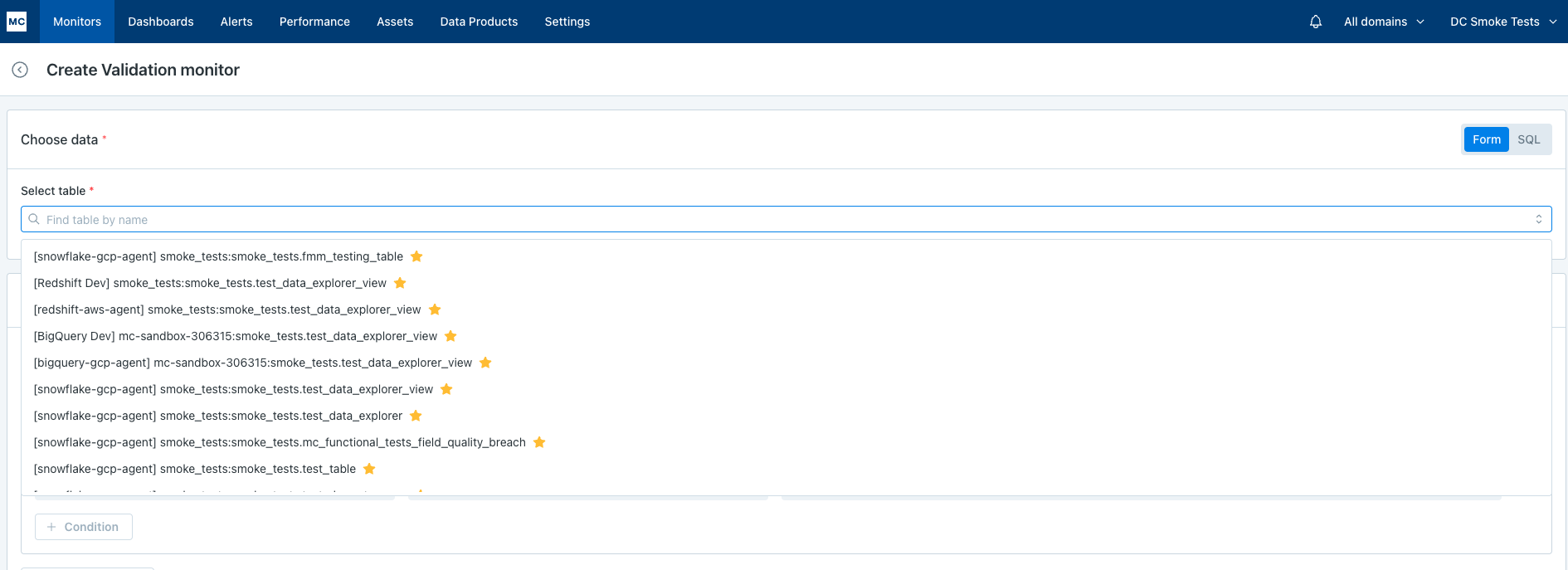
-
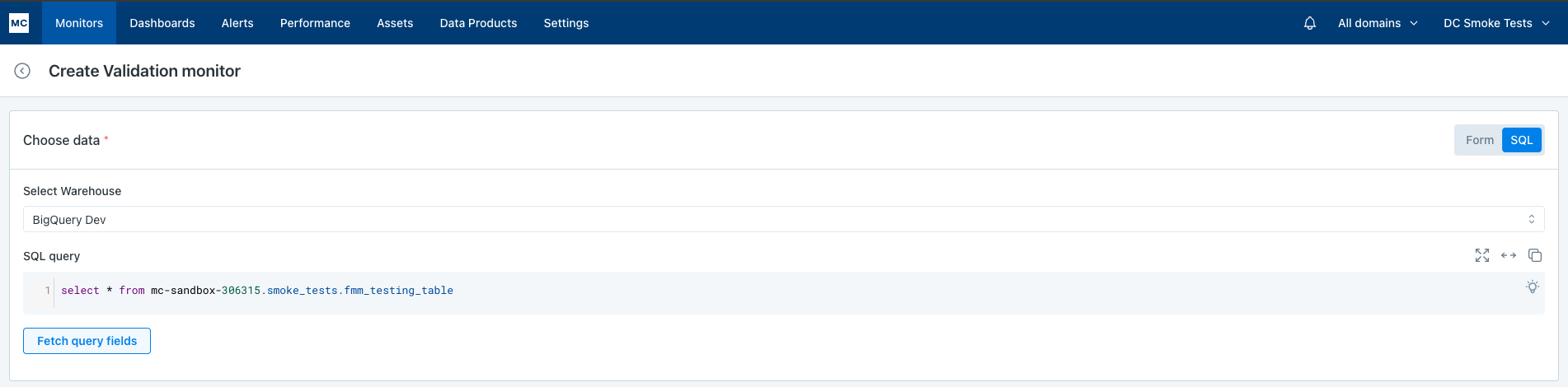
Write a SQL query:
- Select warehouse
- Write a SQL query and click
Testto validate the SQL.
Testwill help users preview all the fields the SQL query returns.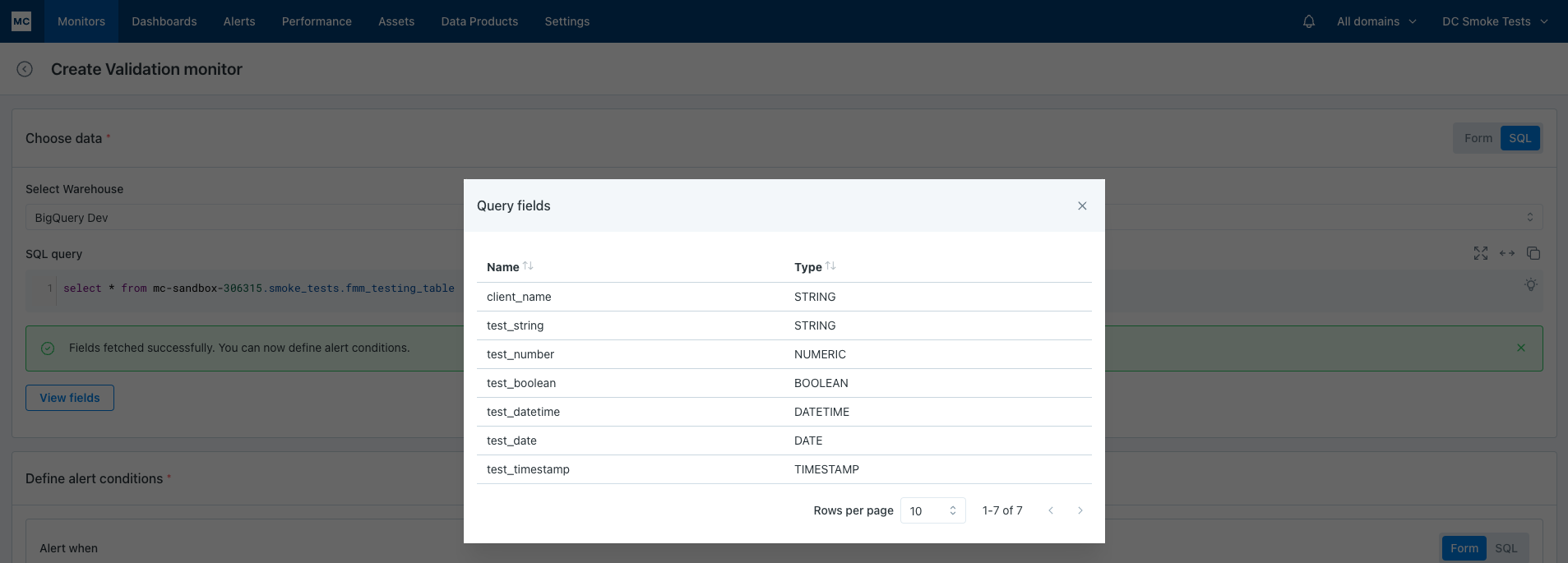
Example: SQL query can be something like
select * from table_name
2. Define alert conditions
Users define alert conditions by adding their own conditions or by getting recommended conditions from the Monitoring agent.
There are 3 types of alert conditions that users can setup when adding their own conditions:
-
Predefined Conditions
Predefined conditions start with
isoperator. Conditions are specific to the data type of field.

-
Conditions with values set by user
These conditions have standard operators for data types like
- numerics: equal, greater_than, greater_than_equal, less_than, less_than_equal, in_set, not_in_set
- date, time: equal, greater_than, greater_than_equal, less_than, less_than_equal
- string: equal, contains, starts_with, ends_with, matches_regex, in_set, not_in_set
- boolean: equal
The user needs to provide a field and a value for these conditions.



-
SQL expressions
For greater flexibility users can also pass in a SQL expression as a condition and test it as well.
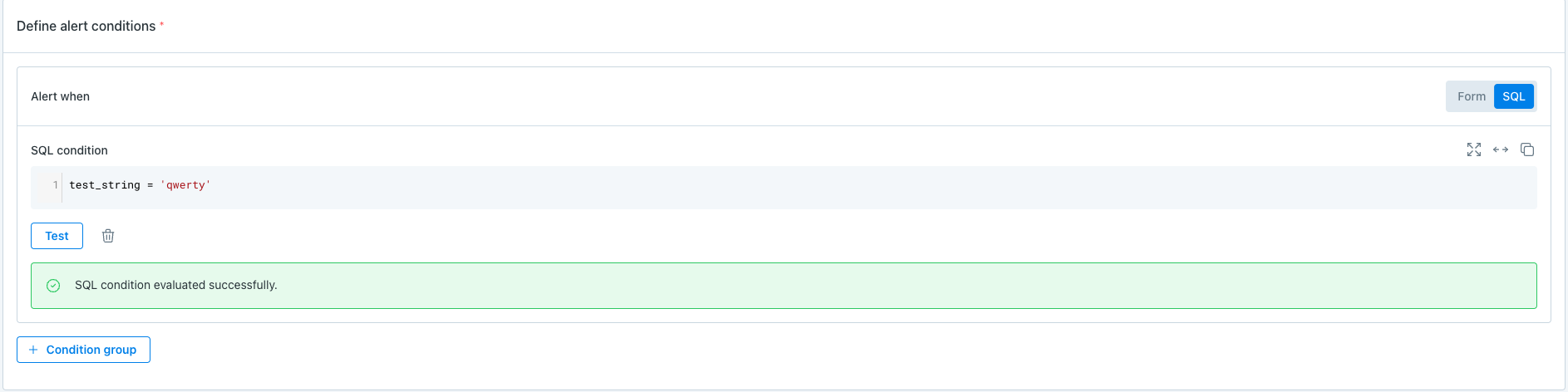
Users can use all of these above conditions to create more complex alert conditions to alert on.
For example: alert conditions combinations like test_string = ‘qwerty’ AND (test_number > 100 OR test_boolean = True) AND test_date > July 12, 2024 will look like this:
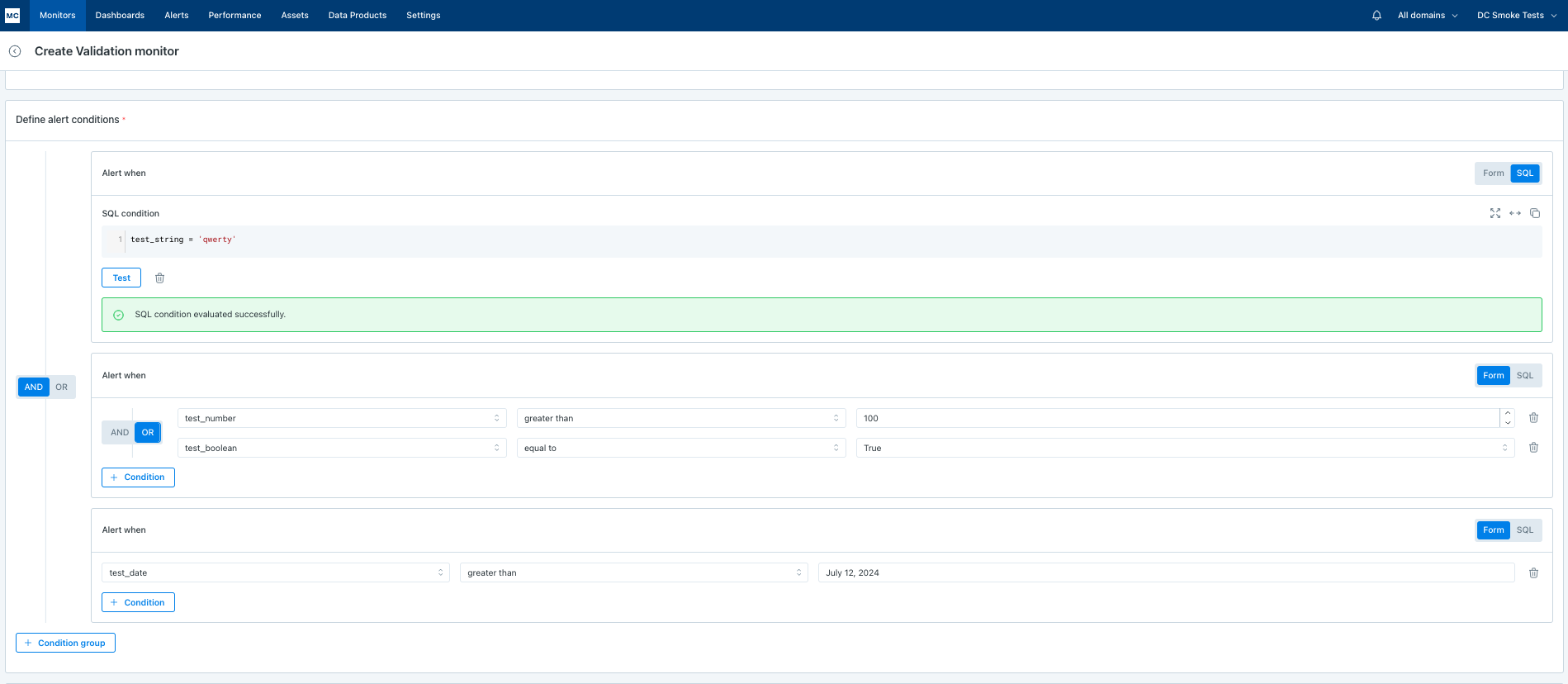
Monitoring agent recommendations
The Monitoring agent recommends alert conditions by sampling data of up to 10k rows based on the user-selected time field and time range. Learn more about Monitoring agent recommendations.
3. Set Threshold
Choose how many breached rows trigger an alert:
- Any row (default): alert when one or more rows meet the alert conditions.
- Percentage of total rows: alert only when breached rows exceed a defined percentage of total rows. Useful when small numbers of failures are expected and only a material breach rate should fire an alert.
When Percentage of total rows is selected, configure an operator (greater than, greater than or equal to, equal to) and a percentage value. The baseline (denominator) is determined automatically from the Choose Data step:
- Table or view selected:
COUNT(*)of the selected table at run time. - SQL query as data source: row count returned by the source query at run time.
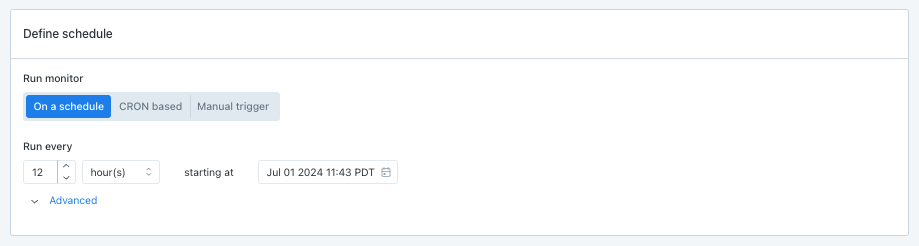
4. Define Schedule
Select when the monitor should run. There are several options:
- On a schedule: Input a regular, periodic schedule. Options for handling daylight savings are available in the advanced dropdown.
- CRON based: Input a cron expression to run on a schedule specified by the cron. Options for handling daylight savings are available in the advanced dropdown.
- By trigger:
- Manual trigger: Select this option when you want to manually trigger using the
Runbutton on the monitor description page. - When a table is updated: The monitor will run when Monte Carlo sees that the table has been updated. This logic uses the history of table updates that Monte Carlo gets through its hourly collection of metadata. The run will occur up to 30 minutes after an update, but not more than once every 2 hours. Use the Run periodically if trigger doesn't fire toggle to control whether the monitor also runs on a fallback schedule (every 48 hours by default) when no table update is detected.
- When a job or task completes: The monitor will run when Monte Carlo detects a successful job or task execution, but not more frequently than every 2 hours. Use the Run periodically if trigger doesn't fire toggle to control whether the monitor also runs on a fallback schedule (every 48 hours by default) when no job or task executions are detected.
- Manual trigger: Select this option when you want to manually trigger using the
5. Send notifications
Select which audiences should receive notifications when an anomaly is detected.
Additional settings exist for setting the description of the monitor which will be set as the header for notifications sent to notification channels, also pre-setting a priority on any incidents generated by the monitor.
See here for more information on Audiences and Notifications. Learn more about setting Monitor tags.
Notes
Text in the Notes section will be included directly in notifications. The "Show notes tips" dropdown includes details on how to @mention an individual or team if you are sending notifications to Slack.
Notes support rich-text formatting, including bold, italic, underline, strike-through, lists, links, and code blocks. Rich-text channels display these styles, while text-only channels show a plain-text equivalent.
Monitor properties can be dynamically inserted into Notes through variables. Supported variables include Created by, Last updated at, Last updated by, Priority, Tags and—for Validation and Custom SQL monitors—Query Result.
Alerts and Notifications
Alerts
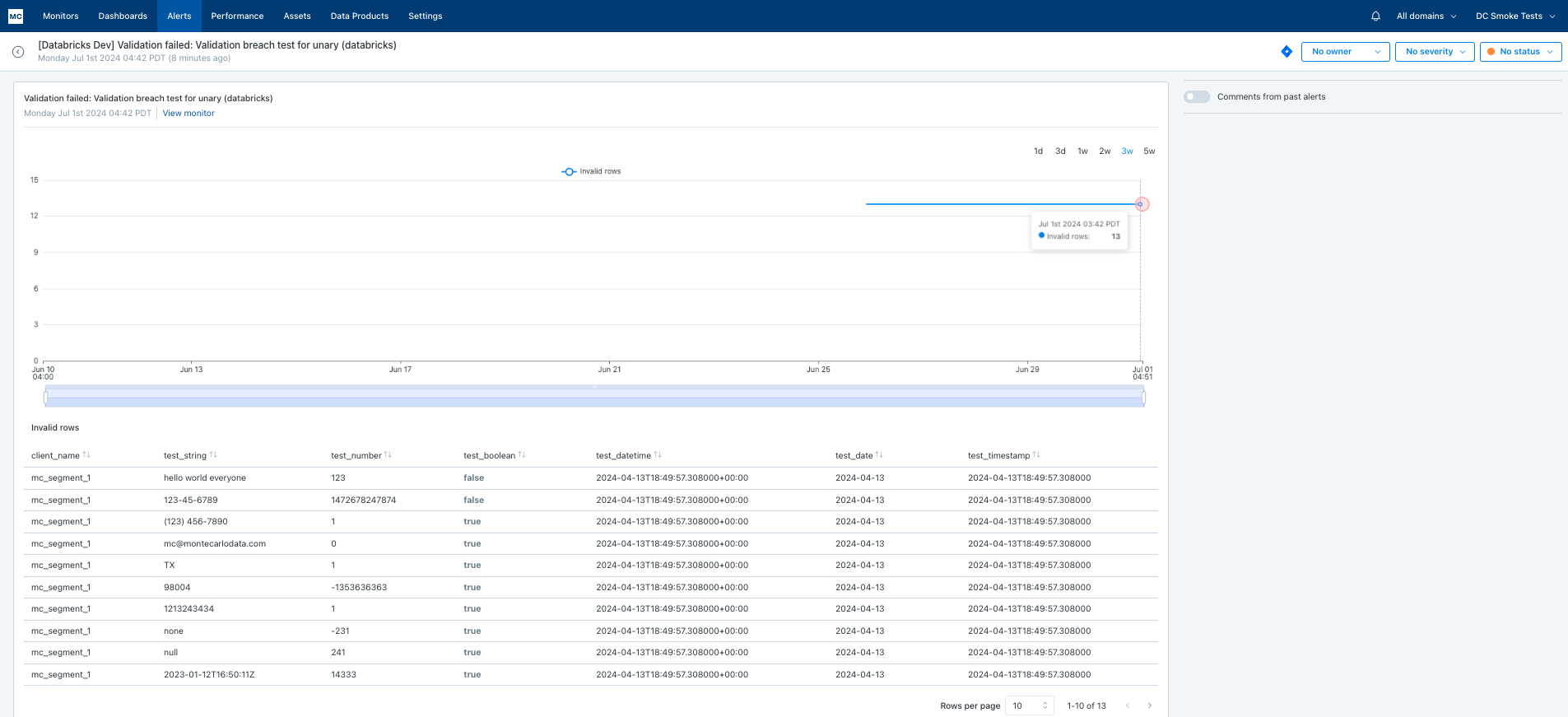
Validation monitors generate an alert whenever at least one row breaches the defined alert condition(s).
Alerts from Validation monitors include the following details:
- Number of rows that breached the alert conditions
- List of the invalid rows
- Historical graph of current and previous breaches
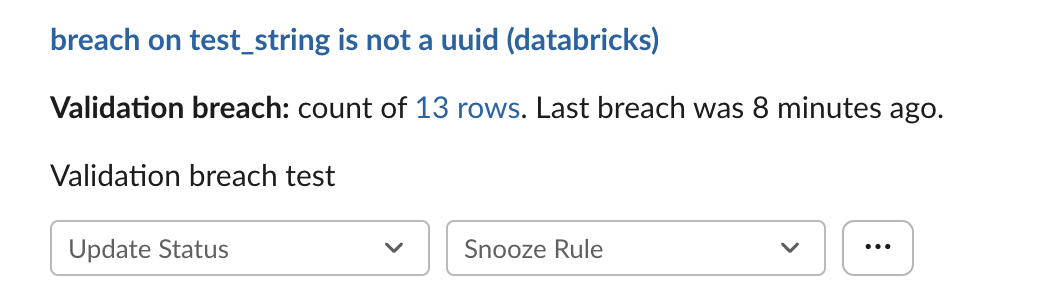
Notifications
Alert notifications are sent to your configured audiences and include:
- Description of the condition that was violated
- Number of rows that breached the alert condition
- When the last breach occurred
Examples
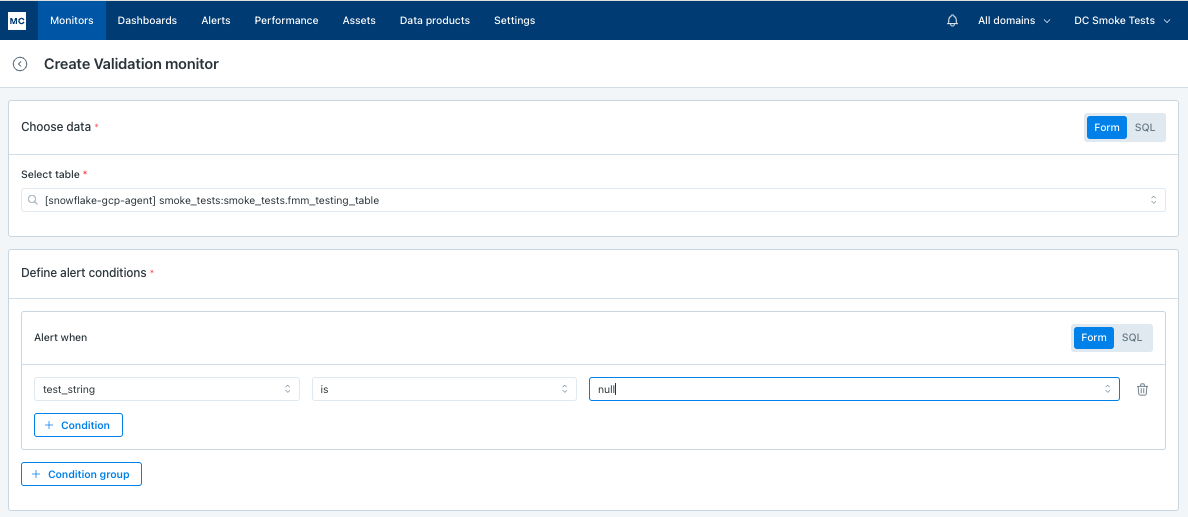
Validate that field values are not null
In this case we need to alert if test_field is null:
Validate that numerical values are not negative
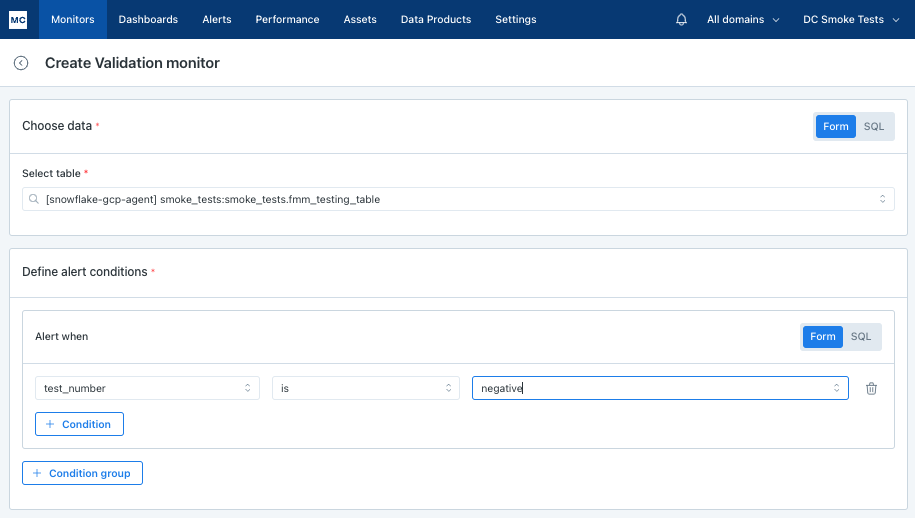
In this case we need to alert if numeric_field is negative:
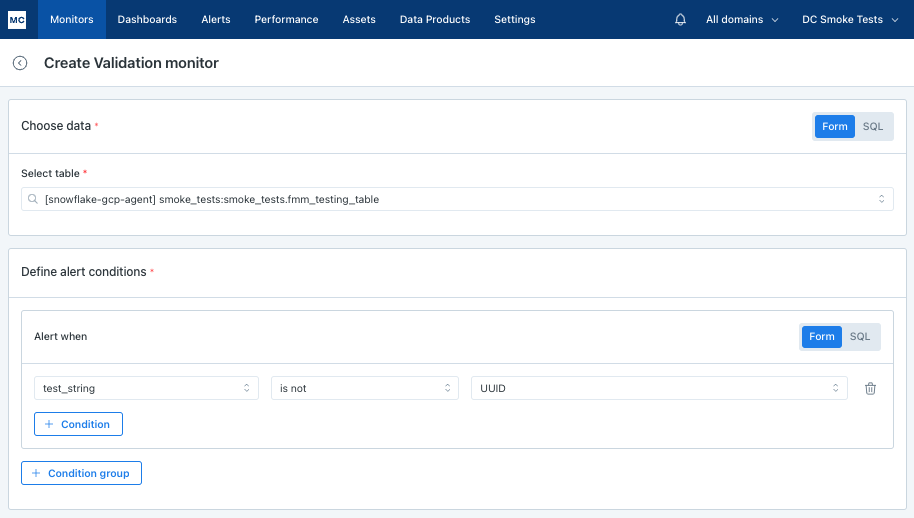
Validate that strings are formatted correctly
In this case we need to alert if string_field is not a specified format, say, uuid - string_field is not UUID:
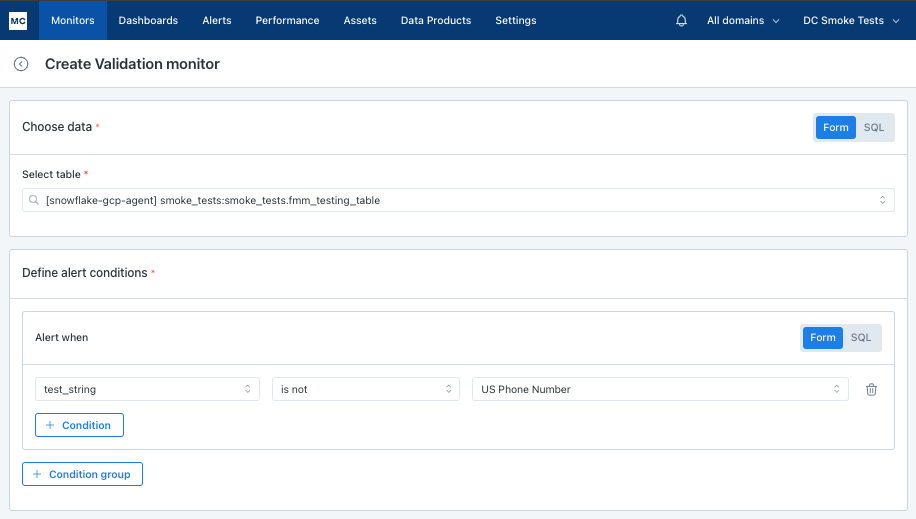
Or alert if us_phone_field is not US phone number:
See here for more formats.
Validate that timestamps are not in the future
In this case we need to alert if timestamp_field is not in the future:
Legacy monitors now included in Validation Monitors
Up until September 2024, Cardinality Rules and Referential Integrity Rules were options on the Monitor Menu in Monte Carlo. These were purpose-built monitor creation experiences that produced a SQL Rule. These were for use cases like:
- Alert me if any of the values in [field] are not included in set [value1, value2, value3, etc]
- Alert me if any of the values in [field] are not present in [table > field]
These were made redundant by Validations, so the experiences to create new ones were removed from the UI. Existing Cardinality Rules and Referential Integrity Rules continue to function.
In Validation Monitors, the recommended way to address these use cases in now with the Is in set and Is not in set operators, which allow a user to define a set:
- From a list: manually enter the values
- From a field: select a table and field, and the set with be populated with the distinct values in that field. The selected field will be referenced each time the monitor is run, so the set values may change.
- From a query: write SQL to define the values in the set. The query will run each time the monitor is run, so the set values may change.
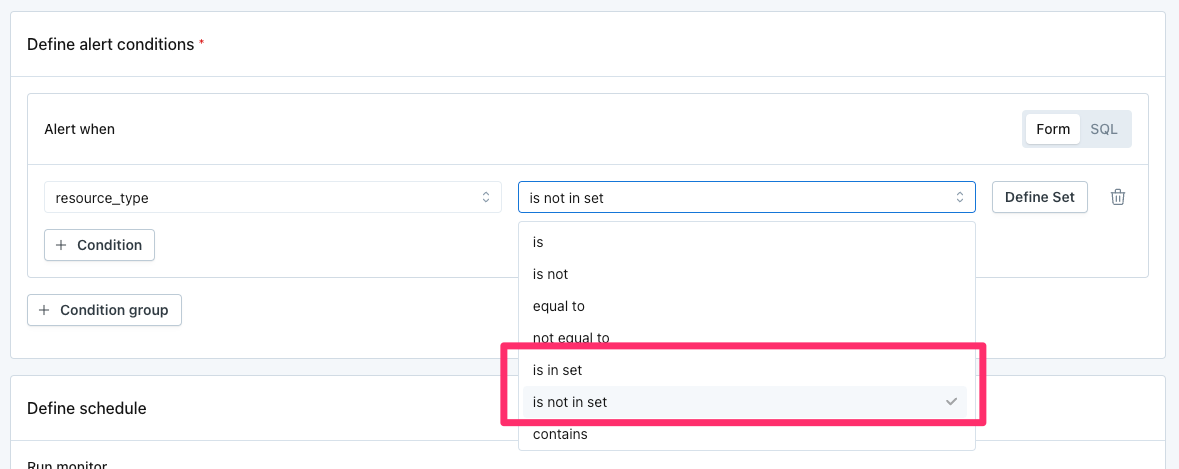
Is in set and Is not in set operators in Validation Monitors
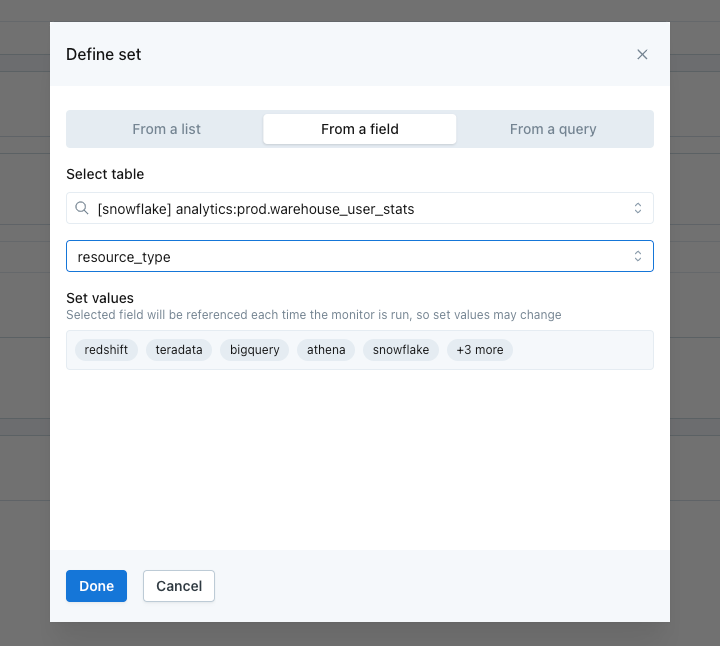
Options to define a set from a list, from a field, or from a query
Updated 1 day ago