Intro to rules-based monitoring
Monte Carlo's rules-based monitors allow you to set breach conditions and breach thresholds for your data. In contrast to automated and opt-in monitoring, our rules-based monitors do not use ML-generated thresholds (with the exception of SQL rules), and therefore are best used when you have specific observability use cases that you want to check for in your data.
Learn about the rules-based monitoring options you have available in Monte Carlo below!
Rule-based monitors types
These are monitors in which you define the logical checks and breach thresholds that you want to observe.
Comparison Rule
Learn more about comparison rules here.
Cardinality Rule
Cardinality rules in Monte Carlo allow you to ensure that a particular column (or set of columns across multiple tables) contains expected values.
To illustrate the use of a cardinality rule, let's use an example. In your organization, you may have a tracking design plan for frontend interactions that your engineers should abide by to keep naming conventions consistent. This is important because you use the regularity of these naming conventions to later model the data with an automated job.
In the tracking plan, your engineers should send over information about the user interacting with the frontend. One of the user attributes you need is user_status, which should be one of the following values:
active, inactive, pendingBecause your data model requires one of these values to be present, you want to monitor incoming data into a raw table to ensure that engineers are conforming to the list of expected values for this field.
With cardinality rules, you can provide a list of values (like the one above) and Monte Carlo will check that column to either:
- Ensure that no other values aside from your list are present (this is called
Allowed valuesin the monitor's settings). For instance, if a new valueunknownappeared, you would be alerted). - Ensure that values in your list are included in the data (this is called
Never-missing valuesin the monitor's settings). For instance, if a column was missing the valuepending, you would be alerted).
In addition, you can also ensure that the cardinality of a column does not breach a certain threshold (this is called Count distinct in the monitor's settings). For instance, if you set count distinct to alert when distinct values were greater than 3, you would be alerted if 5 distinct values showed up).
Note that this monitor type can be used as an extension to the dimension tracking monitor which looks at the historical distribution of distinct values in a column and uses ML to alert you to deviations.
Field Metric Rule
Field metric rules (with manual detection) allow you to ensure that a data quality metric calculated on a particular column (or set of columns across multiple tables) does not deviate from a threshold that you set for it.
Field metric rules can be used as an extension of field metric monitors with automated detection which measure historical values for a set of data quality metrics on columns and use ML to alert you to deviations.
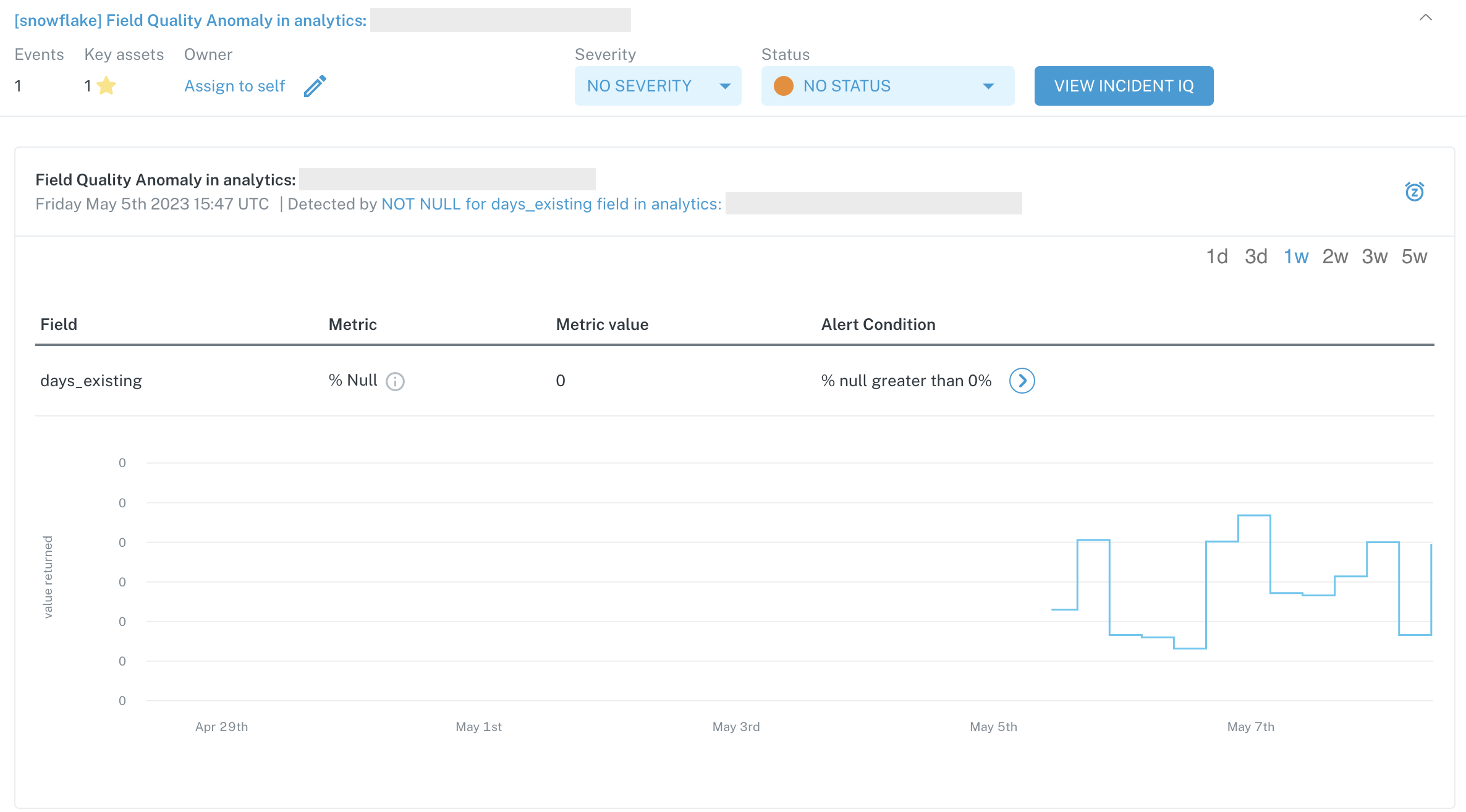
Example incident generated by a Field Metric Rule
To illustrate the use of a field metric rule, suppose that you are a SaaS organization and you have a column named customer_id that exists across 10 different tables (e.g. a table with one row per interaction, a table with a Salesforce sync for accounts, a table with a Salesforce sync for contracts, and several rolled up analytics tables pertaining to customers, etc.). Because this customer_id is the linking identifier to map all of your data with, you need to ensure that there are never null values present in these columns.
With field metric rules, you can set up a rule that looks at the customer_id column in those 10 tables and uses the % null metric and a breach threshold of greater than 0%. A field metric rule set up in this way will alert you if any of the customer_id columns in the 10 tables you select have a null value (which will throw the data quality metric to a non-zero value).
Depending on the data type of the column you select, you have a wide variety of field-level data quality metrics that you can select to build field quality rules on — for instance, median, mean and % negative for numeric data types, and % unique, % null and max length for string data types.
Click here to learn more about field metric rules.
Freshness Rule
Freshness rules in Monte Carlo allow you to run metadata freshness checks on tables where you might need to check for for specific freshness updates on a custom schedule. Freshness rules can be seen as an extension of Monte Carlo's automated freshness monitoring which uses historical patterns and ML to alert you to freshness anomalies.
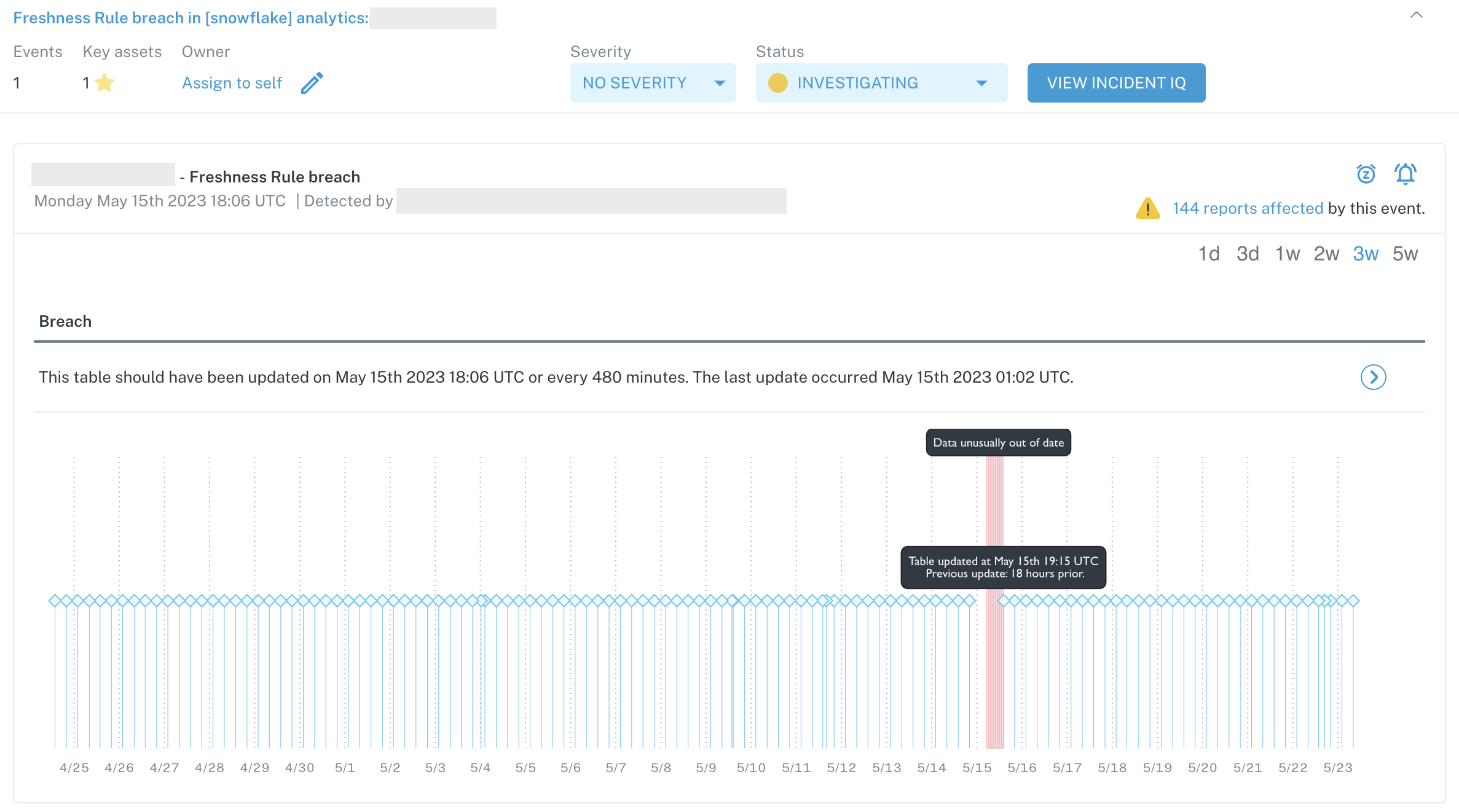
Example incident generated by a Freshness Rule
You might want to apply a freshness rule if you have a specific use case for when data arrives (or is refreshed) in a table that Monte Carlo's automated monitoring would otherwise take too long or not be sensitive enough to alert you on (for reference, this is because our automated monitoring specifically looks for high confidence anomalous behavior to not inundate you with noise).
As an example, you have a table that gets used by stakeholders in the business for their daily operations that you need to have updated every weekday morning as a doublecheck to ensure the overnight job ran successfully. While automated monitoring will pick up lapses in freshness, it may take longer than you want to be notified of this. This is a perfect scenario of when a freshness rule could be applied.
Another example of a good use case for freshness rules is on a table with streaming inserts or micro-batched loads. Due to the high update frequency of these tables, the metadata polling that we do for automated monitoring may not be frequent enough, in which case a freshness rule would be a great monitor to enable.
With freshness rules, you can define an update period and an interval period and Monte Carlo will check your metadata tables to ensure these updates have occurred in the timeframe you specify. Learn more about freshness rules here.
Volume Rule
Volume rules in Monte Carlo allow you to run metadata checks on expected changes in row or byte count of a table on a schedule of your choosing. Volume rules can be seen as an extension of Monte Carlo's automated volume monitoring which uses historical patterns and ML to alert you to volume anomalies.
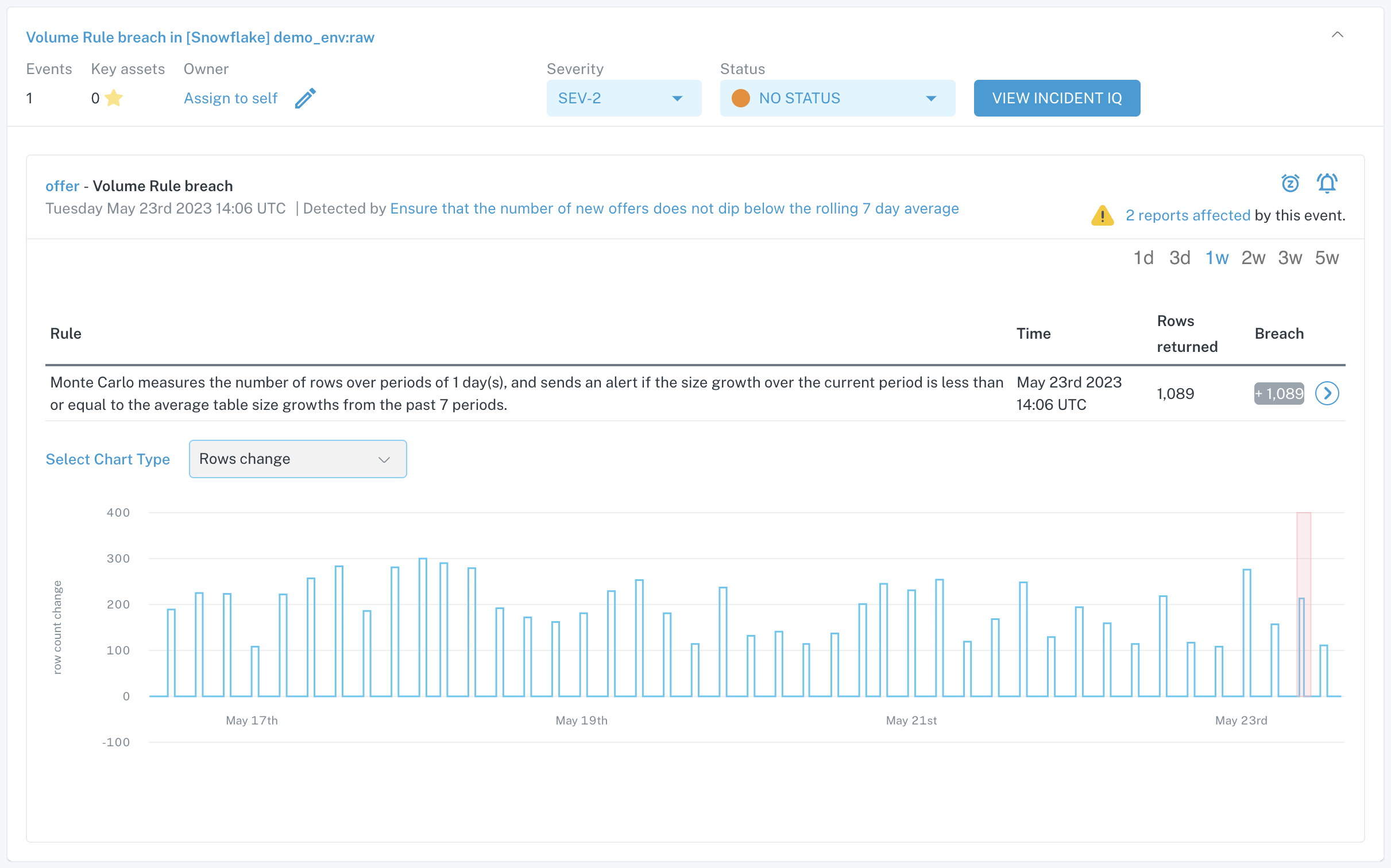
Example incident generated by a Volume Rule
You might want to apply a volume rule when you have a specific logical condition you want to enforce for how a table grows or shrinks over time. You may notice that your automated volume monitoring sets upper and lower bounds for the amount of rows expected on the next metadata check. These bounds adapt with historical data, and are fairly broad as we only want to alert you on high confidence anomalies.
As an example, you may have a raw table that has append-only data from an external source. Because of the nature of the table being append-only, you would expect that the row count for the table would never decrease outside of an anomalous event. This is the perfect use case to enable a volume rule on the table, which can be set up to alert you if the table size decreases even by 1 row.
With volume rules, you have a lot of flexibility to define the type of row/size behavior you need to be alerted on and when the monitor runs. Learn more about all of the features available with volume rules here.
SQL Rule
SQL rules in Monte Carlo allow you to run completely custom checks on your data in any scenario where you are looking for anomalous rows or an anomalous value. Most tests or checks that can be done with a SQL query (including CTEs, joins, analytic functions, etc.) can be set up as SQL rules. You can even port over dbt tests so that they can be centralized in Monte Carlo as SQL rules.
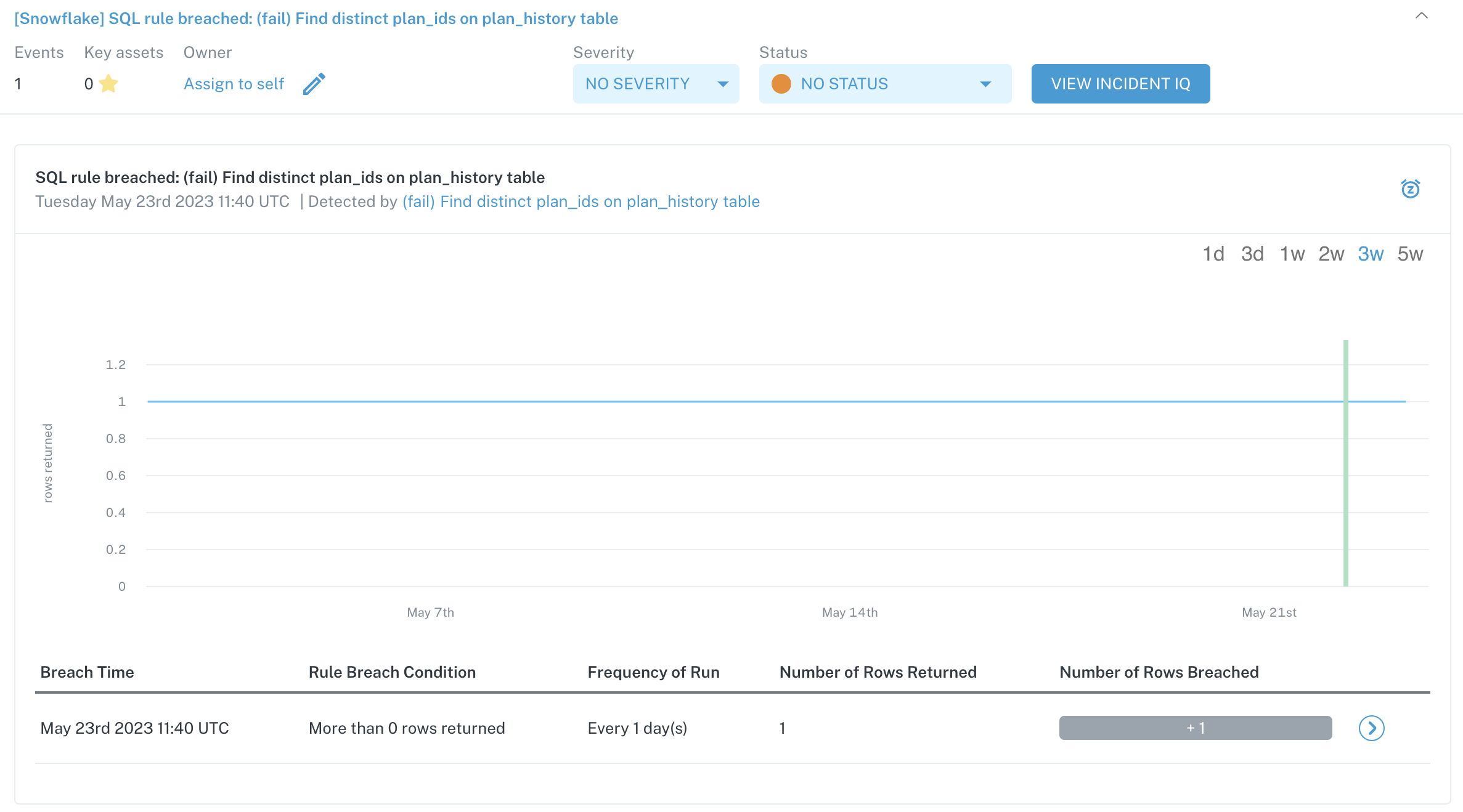
Example incident generated from a SQL Rule
Example use cases for SQL rules can be quite varied — for instance, you can:
- Set up referential checks to ensure that the count distinct of a primary key in one table match the count distinct in a foreign table
- Create a calculated metric and compare it against historical values (e.g. subscription signups today versus the same period a day ago, a week ago, two weeks ago, etc.)
- Create sanity checks with custom logic for highly modeled data (e.g. a customer 360 table where is it known what conditions can and cannot occur, like a customer in the table must have an active contract)
The use cases above are just a sample of the flexibility that SQL rules provide. You can learn more about all of the features available with SQL rules here.
Frequently Asked Questions
Can you use volume and freshness rules on views or data lake tables?
We currently do not support volume and freshness rules on views or data lake tables. We would recommend either setting up field health monitors on those data assets (which track volume changes and unchanged size out of the box) or setting up custom SQL rules to look for row changes.